



–С–Њ–ї—М—И–Є–µ –і–∞–љ–љ—Л–µ –Є –∞–љ–∞–ї–Є—В–Є–Ї–∞ –Њ—В–Ї—А—Л–≤–∞—О—В –њ–µ—А–µ–і –±–Є–Ј–љ–µ—Б–Њ–Љ –њ—А–Є–љ—Ж–Є–њ–Є–∞–ї—М–љ–Њ –љ–Њ–≤—Л–µ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В–Є. –£—З–∞—Б—В–љ–Є–Ї–Є —Б–µ–Ї—Ж–Є–Є ¬Ђ–С–Њ–ї—М—И–Є–µ –і–∞–љ–љ—Л–µ –Є –±–Є–Ј–љ–µ—Б-–∞–љ–∞–ї–Є—В–Є–Ї–∞¬ї –Њ—З–µ—А–µ–і–љ–Њ–≥–Њ ¬ЂCNews FORUM –Ъ–µ–є—Б—Л: –Ю–њ—Л—В –Ш–Ґ-–ї–Є–і–µ—А–Њ–≤ 2022¬ї –Њ–±—Б—Г–і–Є–ї–Є, –Ї–∞–Ї–Є–µ –Ј–∞–і–∞—З–Є –Є –Ї–∞–Ї–Є–Љ–Є –Є–љ—Б—В—А—Г–Љ–µ–љ—В–∞–Љ–Є –Љ–Њ–ґ–љ–Њ —А–µ—И–∞—В—М. –Ь–Њ–ґ–љ–Њ –ї–Є –і–Њ–≤–µ—А–Є—В—М—Б—П –Љ–Њ–і–µ–ї—П–Љ –Љ–∞—И–Є–љ–љ–Њ–≥–Њ –Њ–±—Г—З–µ–љ–Є—П? –І—В–Њ –і–µ–ї–∞—В—М, –µ—Б–ї–Є –Ј–∞–њ–∞–і–љ—Л–µ —А–µ—И–µ–љ–Є—П –љ–µ–і–Њ—Б—В—Г–њ–љ—Л?
–Э–Њ–≤—Л–µ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В–Є –Є–Ј–≤–µ—Б—В–љ—Л—Е —А–µ—И–µ–љ–Є–є
–° —А–Њ—Б—Б–Є–є—Б–Ї–Њ–≥–Њ —А—Л–љ–Ї–∞ —Г—Е–Њ–і—П—В –Ј–∞–њ–∞–і–љ—Л–µ –Є–≥—А–Њ–Ї–Є, –Є –і–ї—П –Њ—В–µ—З–µ—Б—В–≤–µ–љ–љ—Л—Е –Ї–Њ–Љ–њ–∞–љ–Є–є —Н—В–Њ –Ј–љ–∞—З–Є—В –ї–Є—И—М –Њ–і–љ–Њ вАФ –њ—А–Є—И–ї–Њ –≤—А–µ–Љ—П –Љ–Є–≥—А–Є—А–Њ–≤–∞—В—М –љ–∞ –љ–Њ–≤—Л–µ –њ–ї–∞—В—Д–Њ—А–Љ—Л. –Я—Г—В—М —В–µ—А–љ–Є—Б—В: –Ї–Њ–Љ–њ–µ—В–µ–љ—Ж–Є–є –і–ї—П —В–Њ–≥–Њ, —З—В–Њ–±—Л –њ–Є—Б–∞—В—М —Б–Њ–±—Б—В–≤–µ–љ–љ—Л–µ —А–µ—И–µ–љ–Є—П, —З–∞—Б—В–Њ –љ–µ —Е–≤–∞—В–∞–µ—В. –Ш –і–∞–ґ–µ —В–µ –Ї–Њ–Љ–њ–∞–љ–Є–Є, –Ї–Њ—В–Њ—А—Л–µ –і–∞–≤–љ–Њ –Є—Б–њ–Њ–ї—М–Ј—Г—О—В –Њ—В–µ—З–µ—Б—В–≤–µ–љ–љ—Л–µ —А–µ—И–µ–љ–Є—П, –Ј–∞–і—Г–Љ—Л–≤–∞—О—В—Б—П, —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—В –ї–Є –Њ–љ–Є –≤—Б–µ–Љ —В—А–µ–±–Њ–≤–∞–љ–Є—П–Љ –њ–Њ –≥–Є–±–Ї–Њ—Б—В–Є, –±—Л—Б—В—А–Њ–і–µ–є—Б—В–≤–Є—О. –Ъ–∞–Ї –±—Л—В—М –≤ —Н—В–Њ–є —Б–Є—В—Г–∞—Ж–Є–Є, —А–∞—Б—Б–Ї–∞–Ј–∞–ї–∞ –≤ —Б–≤–Њ–µ–Љ –≤—Л—Б—В—Г–њ–ї–µ–љ–Є–Є –Ш—А–Є–љ–∞ –І–µ—А–љ–Њ–≥—Г–Ј–Њ–≤–∞, –≥–ї–∞–≤–љ—Л–є –Ї–Њ–љ—Б—Г–ї—М—В–∞–љ—В EPM-–њ—А–∞–Ї—В–Є–Ї–Є ¬Ђ–Ь–Ъ–°–Ъ–Њ–Љ¬ї.
¬Ђ–Ь–Ъ–°–Ъ–Њ–Љ¬ї вАФ –Є–љ—В–µ–≥—А–∞—В–Њ—А —Б 20 –≥–Њ–і–∞–Љ–Є –њ—А–Њ–µ–Ї—В–љ–Њ–≥–Њ –Њ–њ—Л—В–∞ –љ–∞ –њ–ї–∞—В—Д–Њ—А–Љ–µ 1C –і–ї—П –Ї—А—Г–њ–љ–µ–є—И–Є—Е –≥–Њ—Б—Г–і–∞—А—Б—В–≤–µ–љ–љ—Л—Е –Є —З–∞—Б—В–љ—Л—Е –Ј–∞–Ї–∞–Ј—З–Є–Ї–Њ–≤. –Ъ–Њ–Љ–њ–∞–љ–Є—П —А–∞–Ј—А–∞–±–Њ—В–∞–ї–∞ —Б–≤–Њ—О low-code-–њ–ї–∞—В—Д–Њ—А–Љ—Г EPM, –Ї–Њ—В–Њ—А–∞—П –њ–Њ–Љ–Њ–≥–∞–µ—В —А–∞–±–Њ—В–∞—В—М —Б –Љ–µ–ґ–і—Г–љ–∞—А–Њ–і–љ—Л–Љ–Є —Б—В–∞–љ–і–∞—А—В–∞–Љ–Є —Д–Є–љ–∞–љ—Б–Њ–≤–Њ–є –Њ—В—З–µ—В–љ–Њ—Б—В–Є, —Д–Њ—А–Љ–Є—А–Њ–≤–∞—В—М –Њ—В—З–µ—В–љ–Њ—Б—В—М –і–ї—П –Њ—А–≥–∞–љ–Њ–≤ –Є—Б–њ–Њ–ї–љ–Є—В–µ–ї—М–љ–Њ–є –≤–ї–∞—Б—В–Є, –∞ —В–∞–Ї–ґ–µ –Ј–∞–љ–Є–Љ–∞—В—М—Б—П –±—О–і–ґ–µ—В–Є—А–Њ–≤–∞–љ–Є–µ–Љ. –Я–ї–∞—В—Д–Њ—А–Љ–∞ EPM –њ—А–µ–і–љ–∞–Ј–љ–∞—З–µ–љ–∞ –і–ї—П –Љ–Њ–і–µ—А–љ–Є–Ј–∞—Ж–Є–Є —Д–Є–љ–∞–љ—Б–Њ–≤–Њ–≥–Њ –Є —Г–њ—А–∞–≤–ї–µ–љ—З–µ—Б–Ї–Њ–≥–Њ –Ї–Њ–љ—В—Г—А–Њ–≤. –°—А–µ–і–Є –µ–µ –њ—А–µ–Є–Љ—Г—Й–µ—Б—В–≤ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М –љ–∞—Б—В—А–∞–Є–≤–∞—В—М –љ–µ–Њ–≥—А–∞–љ–Є—З–µ–љ–љ–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –∞–љ–∞–ї–Є—В–Є–Ї, —А–∞–±–Њ—В–∞—В—М —Б –Љ–Є–ї–ї–Є–∞—А–і–∞–Љ–Є –Ј–∞–њ–Є—Б–µ–є –≤ –±–Њ–ї—М—И–Є—Е —В–∞–±–ї–Є—Ж–∞—Е –љ–∞ —Б–Њ—В–љ–Є –Ї–Њ–ї–Њ–љ–Њ–Ї. –°–Ї–Њ—А–Њ—Б—В—М –Њ–±—А–∞–±–Њ—В–Ї–Є –і–∞–љ–љ—Л—Е –Љ–Њ–ґ–µ—В –≤ 100 —А–∞–Ј –њ—А–µ–≤–Њ—Б—Е–Њ–і–Є—В—М —В–∞–Ї–Њ–≤—Г—О –≤ —Г–љ–∞—Б–ї–µ–і–Њ–≤–∞–љ–љ—Л—Е —Б–Є—Б—В–µ–Љ–∞—Е, –љ—Г–ґ–і–∞—О—Й–Є—Е—Б—П –≤ –Ј–∞–Љ–µ–љ–µ.
¬Ђ–£–љ–Є–≤–µ—А—Б–∞–ї—М–љ–Њ—Б—В—М –љ–∞—И–µ–≥–Њ —А–µ—И–µ–љ–Є—П –Њ–±–µ—Б–њ–µ—З–Є–≤–∞–µ—В—Б—П –љ–µ—Б–Ї–Њ–ї—М–Ї–Є–Љ–Є —Д–∞–Ї—В–Њ—А–∞–Љ–Є: –≤–Њ-–њ–µ—А–≤—Л—Е, –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М—О –њ—А–Є–Љ–µ–љ–µ–љ–Є—П –≤ –Ї–Њ–Љ–њ–∞–љ–Є—П—Е –ї—О–±–Њ–≥–Њ —Б–µ–≥–Љ–µ–љ—В–∞ вАФ –Њ—В –Љ–∞–ї—Л—Е –і–Њ —Б–∞–Љ—Л—Е –Ї—А—Г–њ–љ—Л—Е. –Т–Њ-–≤—В–Њ—А—Л—Е, –њ—А–Њ–і—Г–Ї—В –Љ–Њ–ґ–µ—В –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М—Б—П –Є —Б–∞–Љ–Њ—Б—В–Њ—П—В–µ–ї—М–љ–Њ, –Є –≤ –≤–Є–і–µ —А–∞—Б—И–Є—А–µ–љ–Є—П –Ї —А–µ—И–µ–љ–Є—П–Љ —Б–µ–Љ–µ–є—Б—В–≤–∞ 1C. –Э–∞–Ї–Њ–љ–µ—Ж, –њ–ї–∞—В—Д–Њ—А–Љ–∞ –њ–Њ–Ј–≤–Њ–ї—П–µ—В —В–µ–Љ –Ї–Њ–Љ–њ–∞–љ–Є—П–Љ, –Ї–Њ—В–Њ—А—Л–µ —А–∞–љ—М—И–µ –љ–µ —А–∞–±–Њ—В–∞–ї–Є —Б 1C, –Ј–∞–є—В–Є –љ–∞ —Н—В–Њ –њ–Њ–ї–µ, –Є —В–µ–Љ, –Ї—В–Њ —Б—З–Є—В–∞–µ—В, —З—В–Њ ¬Ђ1–°: –£–њ—А–∞–≤–ї–µ–љ–Є–µ —Е–Њ–ї–і–Є–љ–≥–Њ–Љ¬ї вАФ —Н—В–Њ –і–Њ—А–Њ–≥–Њ. –І–µ—В–≤–µ—А—В—Л–Љ —Д–∞–Ї—В–Њ—А–Њ–Љ —П–≤–ї—П–µ—В—Б—П –Љ–Њ–і—Г–ї—М–љ–∞—П –∞—А—Е–Є—В–µ–Ї—В—Г—А–∞. –Ю–љ–∞ –њ–Њ–Ј–≤–Њ–ї—П–µ—В –њ–µ—А–µ—Е–Њ–і–Є—В—М –љ–∞ –њ—А–Њ–і—Г–Ї—В –њ–ї–∞–≤–љ–Њ –Є –±–µ–Ј–±–Њ–ї–µ–Ј–љ–µ–љ–љ–Њ, –Њ—Б–Њ–±–µ–љ–љ–Њ –≤ —Г—Б–ї–Њ–≤–Є—П—Е —Н–Ї–Њ–љ–Њ–Љ–Є–Є –±—О–і–ґ–µ—В–Њ–≤ –љ–∞ –Ш–Ґ¬ї, вАФ –њ–Њ—П—Б–љ–Є–ї–∞ –Ш—А–Є–љ–∞ –І–µ—А–љ–Њ–≥—Г–Ј–Њ–≤–∞.
–І—В–Њ–±—Л –і–Њ–Ї–∞–Ј–∞—В—М –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М —А–∞–±–Њ—В—Л —Б–≤–Њ–µ–≥–Њ —А–µ—И–µ–љ–Є—П —Б 1–° –љ–µ —В–Њ–ї—М–Ї–Њ –љ–∞ –Љ–∞–ї—Л—Е –Є —Б—А–µ–і–љ–Є—Е –њ—А–µ–і–њ—А–Є—П—В–Є—П—Е (—Б—З–Є—В–∞–µ—В—Б—П, —З—В–Њ –Є–Ј-–Ј–∞ –Њ–≥—А–∞–љ–Є—З–µ–љ–Є–є –≤ –њ—А–Њ–≥—А–∞–Љ–Љ–∞—Е –љ–∞ –Ј–∞–њ–Є—Б—М, —З—В–µ–љ–Є–µ –Є –Њ–±—А–∞–±–Њ—В–Ї—Г –±–Њ–ї—М—И–Є—Е –Њ–±—К–µ–Љ–Њ–≤ –і–∞–љ–љ—Л—Е –Ї—А—Г–њ–љ—Л–Љ –Ї–Њ–Љ–њ–∞–љ–Є—П–Љ 1–° –љ–µ –њ–Њ–і–Њ–є–і–µ—В, –љ—Г–ґ–љ–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –Ј–∞–њ–∞–і–љ—Л–µ —А–µ—И–µ–љ–Є—П), –Ш—А–Є–љ–∞ –І–µ—А–љ–Њ–≥—Г–Ј–Њ–≤–∞ —А–∞—Б—Б–Ї–∞–Ј–∞–ї–∞ –Њ –Ї–Њ–љ–Ї—А–µ—В–љ—Л—Е –Ї–µ–є—Б–∞—Е. –Э–∞–њ—А–Є–Љ–µ—А, —Г –Њ–і–љ–Њ–≥–Њ –Є–Ј –Ј–∞–Ї–∞–Ј—З–Є–Ї–Њ–≤, —Д–µ–і–µ—А–∞–ї—М–љ–Њ–≥–Њ –Њ—А–≥–∞–љ–∞ –≤–ї–∞—Б—В–Є, –µ–ґ–µ–Љ–µ—Б—П—З–љ–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –Ј–∞–њ–Є—Б–µ–є –≤ –±–∞–Ј—Г –і–∞–љ–љ—Л—Е —Б–Њ—Б—В–∞–≤–ї—П–ї–Њ 700 –Љ–ї–љ —Б—В—А–Њ–Ї, –µ–ґ–µ–Љ–µ—Б—П—З–љ—Л–є –њ—А–Є—А–Њ—Б—В —Д–∞–є–ї–Њ–≤ CSV вАФ 5 –Ґ–±, –≤—Е–Њ–і—П—Й–Є—Е –∞–љ–∞–ї–Є—В–Є–Ї –≤ –њ—А–µ–ґ–љ–µ–Љ —А–µ—И–µ–љ–Є–Є вАФ 100 —И—В—Г–Ї.
–†–µ–Ј—Г–ї—М—В–∞—В—Л –њ—А–Њ–µ–Ї—В–∞ –і–ї—П —Д–µ–і–µ—А–∞–ї—М–љ–Њ–≥–Њ –Њ—А–≥–∞–љ–∞ –≤–ї–∞—Б—В–Є

–Т –љ–Њ–≤–Њ–Љ —А–µ—И–µ–љ–Є–Є –њ–Њ–Љ–µ–љ—П–ї–Є –∞—А—Е–Є—В–µ–Ї—В—Г—А—Г, —Б—В–∞–ї–Є –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –±—А–Њ–Ї–µ—А —Б–Њ–Њ–±—Й–µ–љ–Є–є –Є –Ї–Њ–ї–Њ–љ–Њ—З–љ–Њ–µ —Е—А–∞–љ–Є–ї–Є—Й–µ, –њ—А–Є–Љ–µ–љ—П—В—М —Б–ї–Њ–≤–∞—А–Є PostgreSQL. –Т–Є–Ј—Г–∞–ї–Є–Ј–∞—Ж–Є—П –≤—Л–њ–Њ–ї–љ—П–ї–∞—Б—М –≤ BI-—Б–Є—Б—В–µ–Љ–µ. ¬Ђ1–° –Љ—Л —Б–Њ—Е—А–∞–љ–Є–ї–Є, –љ–Њ –≤ –Ї–Њ–љ—Ж–µ —Н—В–Њ–є ¬Ђ–њ–Є—Й–µ–≤–Њ–є —Ж–µ–њ–Њ—З–Ї–Є¬ї. –£–і–∞–ї–Њ—Б—М –і–Њ–±–Є—В—М—Б—П —В–Њ–≥–Њ, —З—В–Њ –≤—Е–Њ–і—П—Й–Є–µ –Њ—Б—В–∞—В–Ї–Є –Ј–∞–≥—А—Г–Ј–Є–ї–Є—Б—М –Ј–∞ 4 —З–∞—Б–∞ –њ—А–Њ—В–Є–≤ –і–≤—Г—Е –Љ–µ—Б—П—Ж–µ–≤, –Ї–Њ—В–Њ—А—Л–µ –±—Л –њ–Њ—В—А–µ–±–Њ–≤–∞–ї–Є—Б—М –љ–∞ —З–Є—Б—В–Њ–Љ 1–°. –Т —Ж–µ–ї–Њ–Љ, —Б—В—А—Г–Ї—В—Г—А–∞ —Б—В–∞–ї–∞ –±–Њ–ї–µ–µ —Б–Њ–≤—А–µ–Љ–µ–љ–љ–Њ–є –Є –≤—Л—Б–Њ–Ї–Њ—В–µ—Е–љ–Њ–ї–Њ–≥–Є—З–љ–Њ–є¬ї, вАФ —А–∞—Б—Б–Ї–∞–Ј–∞–ї–∞ –Ш—А–Є–љ–∞ –І–µ—А–љ–Њ–≥—Г–Ј–Њ–≤–∞. –Ґ–µ–њ–µ—А—М –Ї–Њ–љ—Б—Г–ї—М—В–∞–љ—В—Л –Љ–Њ–≥—Г—В —А–∞–±–Њ—В–∞—В—М —Б —Е—А–∞–љ–Є–ї–Є—Й–µ–Љ –і–∞–љ–љ—Л—Е —Б–∞–Љ–Њ—Б—В–Њ—П—В–µ–ї—М–љ–Њ.
–Т —Е–Њ–і–µ —А–∞–±–Њ—В—Л —Б–µ–Ї—Ж–Є–Є —Б–Њ—Б—В–Њ—П–ї—Б—П –њ–µ—А–≤—Л–є –њ—Г–±–ї–Є—З–љ—Л–є –∞–љ–Њ–љ—Б —Б–Њ—В—А—Г–і–љ–Є—З–µ—Б—В–≤–∞ –Љ–µ–ґ–і—Г –Ї–Њ–Љ–њ–∞–љ–Є—П–Љ–Є Arenadata, –њ–Њ—Б—В–∞–≤—Й–Є–Ї–Њ–Љ –њ–ї–∞—В—Д–Њ—А–Љ—Л —Г–њ—А–∞–≤–ї–µ–љ–Є—П –±–Њ–ї—М—И–Є–Љ–Є –і–∞–љ–љ—Л–Љ–Є, –Є –У–Ъ Luxms, –њ–Њ—Б—В–∞–≤—Й–Є–Ї–Њ–Љ BI –Є ETL-—Б–Є—Б—В–µ–Љ (Luxms BI –Є Luxms Data Boring). –Ю–љ–Є –Њ–±—К–µ–і–Є–љ–Є–ї–Є —Г—Б–Є–ї–Є—П –і–ї—П –Њ–±–µ—Б–њ–µ—З–µ–љ–Є—П —Н—Д—Д–µ–Ї—В–Є–≤–љ–Њ–≥–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—П –і–∞–љ–љ—Л—Е —А–Њ—Б—Б–Є–є—Б–Ї–Є–Љ–Є –Њ—А–≥–∞–љ–Є–Ј–∞—Ж–Є—П–Љ–Є.
¬Ђ–°–µ–є—З–∞—Б –Љ—Л –≤–Є–і–Є–Љ –±–Њ–ї—М—И–Њ–є –Є–љ—В–µ—А–µ—Б –Ї—А—Г–њ–љ—Л—Е –Ї–Њ–Љ–њ–∞–љ–Є–є –Ї —В–µ–Љ–µ —Г–њ—А–∞–≤–ї–µ–љ–Є—П –і–∞–љ–љ—Л–Љ–Є –Є –Ї–∞—В–∞–ї–Њ–≥–∞–Љ –і–∞–љ–љ—Л—Е. –І–µ—Б—В–љ–Њ —Б–Ї–∞–ґ—Г, –і–ї—П –Љ–µ–љ—П —Н—В–Њ –њ—А–Є—П—В–љ—Л–є —Б—О—А–њ—А–Є–Ј. –ѓ –≤ —Н—В–Њ–є —Б—Д–µ—А–µ —А–∞–±–Њ—В–∞—О –і–∞–≤–љ–Њ –Є –≤–Є–ґ—Г, –Ї–∞–Ї —А—Л–љ–Њ–Ї —Б—В–∞–љ–Њ–≤–Є—В—Б—П –±–Њ–ї–µ–µ –Ј—А–µ–ї—Л–Љ¬ї, вАФ —Б–Ї–∞–Ј–∞–ї –Ш–≤–∞–љ –Э–Њ–≤–Њ—Б–µ–ї–Њ–≤, –і–Є—А–µ–Ї—В–Њ—А –њ—А–Њ–µ–Ї—В–∞ ¬Ђ–Ъ–∞—В–∞–ї–Њ–≥ –і–∞–љ–љ—Л—Е¬ї, Arenadata.
 –Ш—А–Є–љ–∞ –І–µ—А–љ–Њ–≥—Г–Ј–Њ–≤–∞, –≥–ї–∞–≤–љ—Л–є –Ї–Њ–љ—Б—Г–ї—М—В–∞–љ—В EPM-–њ—А–∞–Ї—В–Є–Ї–Є, –Ь–Ъ–°–Ъ–Њ–Љ: –° —А–Њ—Б—Б–Є–є—Б–Ї–Њ–≥–Њ —А—Л–љ–Ї–∞ —Г—Е–Њ–і—П—В –Ј–∞–њ–∞–і–љ—Л–µ –Є–≥—А–Њ–Ї–Є, –Є –і–ї—П –Њ—В–µ—З–µ—Б—В–≤–µ–љ–љ—Л—Е –Ї–Њ–Љ–њ–∞–љ–Є–є —Н—В–Њ –Ј–љ–∞—З–Є—В –ї–Є—И—М –Њ–і–љ–Њ вАФ –њ—А–Є—И–ї–Њ –≤—А–µ–Љ—П –Љ–Є–≥—А–Є—А–Њ–≤–∞—В—М –љ–∞ –љ–Њ–≤—Л–µ –њ–ї–∞—В—Д–Њ—А–Љ—Л
–Ш—А–Є–љ–∞ –І–µ—А–љ–Њ–≥—Г–Ј–Њ–≤–∞, –≥–ї–∞–≤–љ—Л–є –Ї–Њ–љ—Б—Г–ї—М—В–∞–љ—В EPM-–њ—А–∞–Ї—В–Є–Ї–Є, –Ь–Ъ–°–Ъ–Њ–Љ: –° —А–Њ—Б—Б–Є–є—Б–Ї–Њ–≥–Њ —А—Л–љ–Ї–∞ —Г—Е–Њ–і—П—В –Ј–∞–њ–∞–і–љ—Л–µ –Є–≥—А–Њ–Ї–Є, –Є –і–ї—П –Њ—В–µ—З–µ—Б—В–≤–µ–љ–љ—Л—Е –Ї–Њ–Љ–њ–∞–љ–Є–є —Н—В–Њ –Ј–љ–∞—З–Є—В –ї–Є—И—М –Њ–і–љ–Њ вАФ –њ—А–Є—И–ї–Њ –≤—А–µ–Љ—П –Љ–Є–≥—А–Є—А–Њ–≤–∞—В—М –љ–∞ –љ–Њ–≤—Л–µ –њ–ї–∞—В—Д–Њ—А–Љ—Л
 –Ш–≤–∞–љ –Э–Њ–≤–Њ—Б–µ–ї–Њ–≤, –і–Є—А–µ–Ї—В–Њ—А –њ—А–Њ–µ–Ї—В–∞ ¬Ђ–Ъ–∞—В–∞–ї–Њ–≥ –і–∞–љ–љ—Л—Е¬ї, Arenadata: –°–µ–є—З–∞—Б –Љ—Л –≤–Є–і–Є–Љ –±–Њ–ї—М—И–Њ–є –Є–љ—В–µ—А–µ—Б –Ї—А—Г–њ–љ—Л—Е –Ї–Њ–Љ–њ–∞–љ–Є–є –Ї —В–µ–Љ–µ —Г–њ—А–∞–≤–ї–µ–љ–Є—П –і–∞–љ–љ—Л–Љ–Є –Є –Ї–∞—В–∞–ї–Њ–≥–∞–Љ –і–∞–љ–љ—Л—Е
–Ш–≤–∞–љ –Э–Њ–≤–Њ—Б–µ–ї–Њ–≤, –і–Є—А–µ–Ї—В–Њ—А –њ—А–Њ–µ–Ї—В–∞ ¬Ђ–Ъ–∞—В–∞–ї–Њ–≥ –і–∞–љ–љ—Л—Е¬ї, Arenadata: –°–µ–є—З–∞—Б –Љ—Л –≤–Є–і–Є–Љ –±–Њ–ї—М—И–Њ–є –Є–љ—В–µ—А–µ—Б –Ї—А—Г–њ–љ—Л—Е –Ї–Њ–Љ–њ–∞–љ–Є–є –Ї —В–µ–Љ–µ —Г–њ—А–∞–≤–ї–µ–љ–Є—П –і–∞–љ–љ—Л–Љ–Є –Є –Ї–∞—В–∞–ї–Њ–≥–∞–Љ –і–∞–љ–љ—Л—Е
 –Ф–Љ–Є—В—А–Є–є –Ф–Њ—А–Њ—Д–µ–µ–≤, –≥–ї–∞–≤–љ—Л–є –Ї–Њ–љ—Б—В—А—Г–Ї—В–Њ—А, –У–Ъ Luxms: Luxms Data Boring –њ–Њ–Љ–Њ–≥–∞–µ—В –Є–љ–ґ–µ–љ–µ—А–∞–Љ –і–∞–љ–љ—Л—Е –Є –∞–љ–∞–ї–Є—В–Є–Ї–∞–Љ –≥–Њ—В–Њ–≤–Є—В—М –і–∞–љ–љ—Л–µ –і–ї—П —Н—Д—Д–µ–Ї—В–Є–≤–љ–Њ–є —Б–Ї–Њ—А–Њ—Б—В–љ–Њ–є –≤–Є–Ј—Г–∞–ї–Є–Ј–∞—Ж–Є–Є –≤ Luxms BI, –Ї–Њ–≥–і–∞ –≤–Є—В—А–Є–љ—Л DWH –љ–µ—Г–і–Њ–±–љ—Л
–Ф–Љ–Є—В—А–Є–є –Ф–Њ—А–Њ—Д–µ–µ–≤, –≥–ї–∞–≤–љ—Л–є –Ї–Њ–љ—Б—В—А—Г–Ї—В–Њ—А, –У–Ъ Luxms: Luxms Data Boring –њ–Њ–Љ–Њ–≥–∞–µ—В –Є–љ–ґ–µ–љ–µ—А–∞–Љ –і–∞–љ–љ—Л—Е –Є –∞–љ–∞–ї–Є—В–Є–Ї–∞–Љ –≥–Њ—В–Њ–≤–Є—В—М –і–∞–љ–љ—Л–µ –і–ї—П —Н—Д—Д–µ–Ї—В–Є–≤–љ–Њ–є —Б–Ї–Њ—А–Њ—Б—В–љ–Њ–є –≤–Є–Ј—Г–∞–ї–Є–Ј–∞—Ж–Є–Є –≤ Luxms BI, –Ї–Њ–≥–і–∞ –≤–Є—В—А–Є–љ—Л DWH –љ–µ—Г–і–Њ–±–љ—Л
 –°—В–∞–љ–Є—Б–ї–∞–≤ –Ы—П—Е–Њ–≤–µ—Ж–Ї–Є–є, –Ј–∞–Љ–µ—Б—В–Є—В–µ–ї—М –≥–µ–љ–µ—А–∞–ї—М–љ–Њ–≥–Њ –і–Є—А–µ–Ї—В–Њ—А–∞, ¬Ђ–Р–Ї—В–Є–≤–С–Є–Ј–љ–µ—Б–Ъ–Њ–љ—Б–∞–ї—В¬ї: –Ш—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ —А–µ—З–µ–≤–Њ–є –∞–љ–∞–ї–Є—В–Є–Ї–Є –њ–Њ–Љ–Њ–≥–ї–Њ –љ–∞–Љ —Г–≤–Є–і–µ—В—М —В—Г —З–∞—Б—В—М –∞–є—Б–±–µ—А–≥–∞, –Ї–Њ—В–Њ—А–∞—П –Њ–±—Л—З–љ–Њ —Б–Ї—А—Л—В–∞ –њ–Њ–і –≤–Њ–і–Њ–є. –° –µ–µ –њ–Њ–Љ–Њ—Й—М—О –љ–∞–Љ —Г–і–∞–ї–Њ—Б—М –Њ–њ—В–Є–Љ–Є–Ј–Є—А–Њ–≤–∞—В—М –љ–µ–Ї–Њ—В–Њ—А—Л–µ –±–Є–Ј–љ–µ—Б-–њ—А–Њ—Ж–µ—Б—Б—Л
–°—В–∞–љ–Є—Б–ї–∞–≤ –Ы—П—Е–Њ–≤–µ—Ж–Ї–Є–є, –Ј–∞–Љ–µ—Б—В–Є—В–µ–ї—М –≥–µ–љ–µ—А–∞–ї—М–љ–Њ–≥–Њ –і–Є—А–µ–Ї—В–Њ—А–∞, ¬Ђ–Р–Ї—В–Є–≤–С–Є–Ј–љ–µ—Б–Ъ–Њ–љ—Б–∞–ї—В¬ї: –Ш—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ —А–µ—З–µ–≤–Њ–є –∞–љ–∞–ї–Є—В–Є–Ї–Є –њ–Њ–Љ–Њ–≥–ї–Њ –љ–∞–Љ —Г–≤–Є–і–µ—В—М —В—Г —З–∞—Б—В—М –∞–є—Б–±–µ—А–≥–∞, –Ї–Њ—В–Њ—А–∞—П –Њ–±—Л—З–љ–Њ —Б–Ї—А—Л—В–∞ –њ–Њ–і –≤–Њ–і–Њ–є. –° –µ–µ –њ–Њ–Љ–Њ—Й—М—О –љ–∞–Љ —Г–і–∞–ї–Њ—Б—М –Њ–њ—В–Є–Љ–Є–Ј–Є—А–Њ–≤–∞—В—М –љ–µ–Ї–Њ—В–Њ—А—Л–µ –±–Є–Ј–љ–µ—Б-–њ—А–Њ—Ж–µ—Б—Б—Л
 –°–µ—А–≥–µ–є –Р–ї–µ—И–Ї–Є–љ, –≥–ї–∞–≤–∞ –і–µ–њ–∞—А—В–∞–Љ–µ–љ—В–∞ Data Science, –°–Ю–У–Р–Ч: –Т –Њ–±–ї–∞—Б—В–Є —Б—В—А–∞—Е–Њ–≤–∞–љ–Є—П 30% –Ї–Њ–Љ–њ–∞–љ–Є–є –њ—А–Є–Љ–µ–љ—П—О—В –Ш–Ш –≤ —В–µ—Е –Є–ї–Є –Є–љ—Л—Е –±–Є–Ј–љ–µ—Б-–њ—А–Њ—Ж–µ—Б—Б–∞—Е, –њ—А–Є —Н—В–Њ–Љ 25% –Ї–ї–Є–µ–љ—В–Њ–≤ —Г–ґ–µ –≥–Њ—В–Њ–≤—Л –њ–Њ–ї–љ–Њ—Б—В—М—О –њ–µ—А–µ–є—В–Є –љ–∞ —Ж–Є—Д—А–Њ–≤–Њ–µ —Б—В—А–∞—Е–Њ–≤–∞–љ–Є–µ
–°–µ—А–≥–µ–є –Р–ї–µ—И–Ї–Є–љ, –≥–ї–∞–≤–∞ –і–µ–њ–∞—А—В–∞–Љ–µ–љ—В–∞ Data Science, –°–Ю–У–Р–Ч: –Т –Њ–±–ї–∞—Б—В–Є —Б—В—А–∞—Е–Њ–≤–∞–љ–Є—П 30% –Ї–Њ–Љ–њ–∞–љ–Є–є –њ—А–Є–Љ–µ–љ—П—О—В –Ш–Ш –≤ —В–µ—Е –Є–ї–Є –Є–љ—Л—Е –±–Є–Ј–љ–µ—Б-–њ—А–Њ—Ж–µ—Б—Б–∞—Е, –њ—А–Є —Н—В–Њ–Љ 25% –Ї–ї–Є–µ–љ—В–Њ–≤ —Г–ґ–µ –≥–Њ—В–Њ–≤—Л –њ–Њ–ї–љ–Њ—Б—В—М—О –њ–µ—А–µ–є—В–Є –љ–∞ —Ж–Є—Д—А–Њ–≤–Њ–µ —Б—В—А–∞—Е–Њ–≤–∞–љ–Є–µ
 –Ш—А–Є–љ–∞ –У–Њ–ї–Њ—Й–∞–њ–Њ–≤–∞, –≥–ї–∞–≤–∞ –і–µ–њ–∞—А—В–∞–Љ–µ–љ—В–∞ Data Science, ¬Ђ–Ы–µ–љ—В–∞¬ї: –Я—А–Њ–≥–љ–Њ–Ј –≤—Л—А—Г—З–Ї–Є –і–ї—П –Ї–Њ–љ–Ї—А–µ—В–љ—Л—Е –ї–Њ–Ї–∞—Ж–Є–є вАУ –Њ—Б–љ–Њ–≤–∞ –±–Є–Ј–љ–µ—Б-–њ—А–Њ—Ж–µ—Б—Б–∞. –Ь–Њ–і–µ–ї—М –і–Њ–ї–ґ–љ–∞ —Г—З–Є—В—Л–≤–∞—В—М –Ї–ї—О—З–µ–≤—Л–µ —Д–∞–Ї—В–Њ—А—Л, —Б–њ–Њ—Б–Њ–±–љ—Л–µ –њ–Њ–≤–ї–Є—П—В—М –љ–∞ —Д–Є–љ–∞–љ—Б–Њ–≤—Г—О –≤—Л–≥–Њ–і—Г –Њ—В –Њ—В–Ї—А—Л—В–Є—П –Љ–∞–≥–∞–Ј–Є–љ–∞ –≤ –Ї—А–∞—В–Ї–Њ–Љ –Є –і–Њ–ї–≥–Њ—Б—А–Њ—З–љ–Њ–Љ –њ–µ—А–Є–Њ–і–∞—Е
–Ш—А–Є–љ–∞ –У–Њ–ї–Њ—Й–∞–њ–Њ–≤–∞, –≥–ї–∞–≤–∞ –і–µ–њ–∞—А—В–∞–Љ–µ–љ—В–∞ Data Science, ¬Ђ–Ы–µ–љ—В–∞¬ї: –Я—А–Њ–≥–љ–Њ–Ј –≤—Л—А—Г—З–Ї–Є –і–ї—П –Ї–Њ–љ–Ї—А–µ—В–љ—Л—Е –ї–Њ–Ї–∞—Ж–Є–є вАУ –Њ—Б–љ–Њ–≤–∞ –±–Є–Ј–љ–µ—Б-–њ—А–Њ—Ж–µ—Б—Б–∞. –Ь–Њ–і–µ–ї—М –і–Њ–ї–ґ–љ–∞ —Г—З–Є—В—Л–≤–∞—В—М –Ї–ї—О—З–µ–≤—Л–µ —Д–∞–Ї—В–Њ—А—Л, —Б–њ–Њ—Б–Њ–±–љ—Л–µ –њ–Њ–≤–ї–Є—П—В—М –љ–∞ —Д–Є–љ–∞–љ—Б–Њ–≤—Г—О –≤—Л–≥–Њ–і—Г –Њ—В –Њ—В–Ї—А—Л—В–Є—П –Љ–∞–≥–∞–Ј–Є–љ–∞ –≤ –Ї—А–∞—В–Ї–Њ–Љ –Є –і–Њ–ї–≥–Њ—Б—А–Њ—З–љ–Њ–Љ –њ–µ—А–Є–Њ–і–∞—Е
–С—Л–≤–∞–µ—В —В–∞–Ї, —З—В–Њ –њ—А–Є –њ–Њ–њ—Л—В–Ї–µ —А–µ—И–Є—В—М –Ї–∞–Ї—Г—О-–љ–Є–±—Г–і—М –њ—А–Є–Ї–ї–∞–і–љ—Г—О –Ј–∞–і–∞—З—Г, –њ–Њ–ї—Г—З–∞–µ—В—Б—П, —З—В–Њ 80% –≤—А–µ–Љ–µ–љ–Є —А–∞—Б—Е–Њ–і—Г–µ—В—Б—П –љ–µ –љ–∞ —А–µ—И–µ–љ–Є–µ –Ї–∞–Ї —В–∞–Ї–Њ–≤–Њ–µ, –∞ –љ–∞ –њ–Њ–Є—Б–Ї –і–∞–љ–љ—Л—Е: —З—В–Њ –µ—Б—В—М —Г –Ї–Њ–Љ–њ–∞–љ–Є–Є, –Љ–Њ–ґ–љ–Њ –ї–Є —Н—В–Њ –њ—А–Є–Љ–µ–љ—П—В—М –љ–∞ –њ—А–∞–Ї—В–Є–Ї–µ –Є –Ї—В–Њ –Ј–∞ —Н—В–Њ –Њ—В–≤–µ—З–∞–µ—В. –Я—А–Є –≤–љ–µ–і—А–µ–љ–Є–Є –Є–љ—Б—В—А—Г–Љ–µ–љ—В–Њ–≤ –і–ї—П —Б–Њ–≤–Љ–µ—Б—В–љ–Њ–є —А–∞–±–Њ—В—Л —Б –і–∞–љ–љ—Л–Љ–Є –Є –Ї–∞—В–∞–ї–Њ–≥–Њ–≤ —Б–Њ–Њ—В–љ–Њ—И–µ–љ–Є–µ –Љ–µ–љ—П–µ—В—Б—П: –і–∞–љ–љ—Л–µ –љ–∞—Е–Њ–і—П—В—Б—П –Ј–∞ –Љ–Є–љ—Г—В—Л, –Є —В–µ–њ–µ—А—М –љ–∞ –Є—Е –∞–љ–∞–ї–Є–Ј, –њ–Њ–і–≥–Њ—В–Њ–≤–Ї—Г –Љ–Њ–і–µ–ї–µ–є –Є –≤—Л–≤–Њ–і—Л —В—А–∞—В—П—В—Б—П 80% –≤—А–µ–Љ–µ–љ–Є, –∞ –љ–µ 20%, –Ї–∞–Ї —А–∞–љ—М—И–µ.
Arenadata –Є Luxms –≤–Љ–µ—Б—В–µ —Б–Њ–Ј–і–∞—О—В –њ—А–Њ–і—Г–Ї—В –і–ї—П –њ–Њ–і–і–µ—А–ґ–Ї–Є –њ—А–Њ—Ж–µ—Б—Б–Њ–≤ Data Governance вАФ Arenadata Catalog. –°—А–µ–і–Є –Њ—Б–љ–Њ–≤–љ—Л—Е –њ—А–Є–љ—Ж–Є–њ–Њ–≤ —А–∞–Ј–≤–Є—В–Є—П –њ—А–Њ–і—Г–Ї—В–∞ –Њ—В–Ї—А—Л—В—Л–µ —Б—В–∞–љ–і–∞—А—В—Л –Є –∞—А—Е–Є—В–µ–Ї—В—Г—А–∞, –∞–≤—В–Њ–Љ–∞—В–Є–Ј–∞—Ж–Є—П —А—Г—В–Є–љ–љ—Л—Е –Ј–∞–і–∞—З —Г–њ—А–∞–≤–ї–µ–љ–Є—П –і–∞–љ–љ—Л–Љ–Є, –њ–Њ–і–і–µ—А–ґ–Ї–∞ –≤—Б–µ–≥–Њ —Ж–Є–Ї–ї–∞ —А–∞–±–Њ—В—Л —Б –і–∞–љ–љ—Л–Љ–Є –Є —Г—А–Њ–≤–љ–µ–є –Є–љ—Д—А–∞—Б—В—А—Г–Ї—В—Г—А—Л, —Д–Њ–Ї—Г—Б –љ–∞ –Ј–∞–і–∞—З–∞—Е –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є. –†–µ—И–µ–љ–Є–µ –±–∞–Ј–Є—А—Г–µ—В—Б—П –љ–∞ Open Source –Ї–Њ–Љ–њ–Њ–љ–µ–љ—В–∞—Е, –Є–љ—В–µ–≥—А–Є—А–Њ–≤–∞–љ–Њ —Б LDAP, —Г–њ—А–∞–≤–ї–µ–љ–Є–µ–Љ —А–Њ–ї—П–Љ–Є –Є –≥—А—Г–њ–њ–∞–Љ–Є, –Є–Љ–µ–µ—В —Д—Г–љ–Ї—Ж–Є–Њ–љ–∞–ї –њ–Њ —Г–њ—А–∞–≤–ї–µ–љ–Є—О —А–∞–±–Њ—З–Є–Љ–Є –њ—А–Њ—Ж–µ—Б—Б–∞–Љ–Є (—Б–Њ–≥–ї–∞—Б–Њ–≤–∞–љ–Є–µ –Є–Ј–Љ–µ–љ–µ–љ–Є–є), –≤–Ї–ї—О—З–∞–µ—В –≤ —Б–µ–±—П –±–Є–Ј–љ–µ—Б-–≥–ї–Њ—Б—Б–∞—А–Є–є –Є –њ–Њ–і–і–µ—А–ґ–Є–≤–∞–µ—В —А—Г—Б—Б–Ї–Є–є —П–Ј—Л–Ї. –Я–Њ–Ї–∞ Arenadata Catalog –љ–∞—Е–Њ–і–Є—В—Б—П –≤ —А–∞–Ј—А–∞–±–Њ—В–Ї–µ.
–Я–ї–∞—Б—В —Б–Њ–≤–Љ–µ—Б—В–љ—Л–є —А–∞–±–Њ—В—Л –±–Њ–ї—М—И–Њ–є. –Ф–Љ–Є—В—А–Є–є –Ф–Њ—А–Њ—Д–µ–µ–≤, –≥–ї–∞–≤–љ—Л–є –Ї–Њ–љ—Б—В—А—Г–Ї—В–Њ—А, –У–Ъ Luxms —А–∞—Б—Б–Ї–∞–Ј–∞–ї –Њ –µ—Й–µ –Њ–і–љ–Њ–Љ –њ—А–Њ–і—Г–Ї—В–µ вАФ Luxms BI Arenadata Platform Edition вАФ –Є –њ—А–µ–Є–Љ—Г—Й–µ—Б—В–≤–∞—Е —Н—В–Њ–≥–Њ –Є–љ—В–µ–≥—А–Є—А–Њ–≤–∞–љ–љ–Њ–≥–Њ —Б –њ–ї–∞—В—Д–Њ—А–Љ–Њ–є –і–∞–љ–љ—Л—Е BI-—А–µ—И–µ–љ–Є—П.
Luxms BI –њ—А–µ–і—Б—В–∞–≤–ї—П–µ—В —Б–Њ–±–Њ–є –≥–Є–±–Ї—Г—О —Б–Є—Б—В–µ–Љ—Г, –њ–Њ–Ј–≤–Њ–ї—П—О—Й—Г—О –љ–∞—А–∞—Й–Є–≤–∞—В—М —Д—Г–љ–Ї—Ж–Є–Њ–љ–∞–ї. –Ю–љ–∞ –і–∞–µ—В –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М –Ј–∞–Ї–∞–Ј—З–Є–Ї—Г —Б–Њ–Ј–і–∞–≤–∞—В—М –Є —Б–≤–Њ–Є –Љ–Є–Ї—А–Њ—Б–µ—А–≤–Є—Б—Л. –Ф–∞–љ–љ—Л–µ –Ј–і–µ—Б—М —Е—А–∞–љ—П—В—Б—П –≤ –≤–Є–і–µ —В—А–µ—Е —Б–ї–Њ–µ–≤: –≥–Њ—А—П—З–µ–≥–Њ (—Б–≤–µ–ґ–Є–µ –і–∞–љ–љ—Л–µ –Ј–∞ –њ–Њ—Б–ї–µ–і–љ–Є–є –≥–Њ–і), —В–µ–њ–ї–Њ–≥–Њ (–і–∞–љ–љ—Л–µ –Ј–∞ 5 –ї–µ—В) –Є —Е–Њ–ї–Њ–і–љ–Њ–≥–Њ. –Я–Њ –Љ–µ—А–µ —Г—Б—В–∞—А–µ–≤–∞–љ–Є—П, –і–∞–љ–љ—Л–µ –њ–µ—А–µ—Е–Њ–і—П—В –љ–∞ —Б–ї–µ–і—Г—О—Й–Є–є —Б–ї–Њ–є —Б –њ–Њ–Љ–Њ—Й—М—О ETL-–Є–љ—Б—В—А—Г–Љ–µ–љ—В–Њ–≤, –љ–Њ –њ—А–Є —Н—В–Њ–Љ –≤—Б—П –њ–ї–∞—В—Д–Њ—А–Љ–∞ –і–Њ–ї–ґ–љ–∞ –њ–Њ–і–і–µ—А–ґ–Є–≤–∞—В—М —В–∞–Ї—Г—О –Ї–Њ–љ—Ж–µ–њ—Ж–Є—О. Arenadata Platform –њ–Њ–Ј–≤–Њ–ї—П–µ—В —Б–Њ–Ј–і–∞–≤–∞—В—М –Є –њ–Њ–і–і–µ—А–ґ–Є–≤–∞—В—М –љ—Г–ґ–љ—Г—О —Б–Є—Б—В–µ–Љ—Г —Е—А–∞–љ–µ–љ–Є—П.
¬Ђ–Ф–ї—П –Ї–Њ–љ–µ—З–љ–Њ–≥–Њ –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—П –њ–Њ —Д—Г–љ–Ї—Ж–Є–Њ–љ–∞–ї—Г –љ–Є—З–µ–≥–Њ –Њ—Б–Њ–±–Њ –љ–µ –Љ–µ–љ—П–µ—В—Б—П, –±—Г–і–µ—В —В–Њ –ґ–µ —П–і—А–Њ, –Ї–Њ—В–Њ—А–Њ–µ –Љ—Л —А–∞–Ј–≤–Є–≤–∞–µ–Љ –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –ї–µ—В. –°–µ–є—З–∞—Б –ґ–µ –±—Л–ї–Є –њ—А–µ–і–њ—А–Є–љ—П—В—Л –Є–љ—В–µ–≥—А–∞—Ж–Є–Њ–љ–љ—Л–µ —Г—Б–Є–ї–Є—П, —З—В–Њ–±—Л Luxms BI —Г—Б—В–∞–љ–∞–≤–ї–Є–≤–∞–ї—Б—П –Є —Н–Ї—Б–њ–ї—Г–∞—В–Є—А–Њ–≤–∞–ї—Б—П —В–∞–Ї –ґ–µ, –Ї–∞–Ї –≤—Б–µ –Њ—Б—В–∞–ї—М–љ—Л–µ –Ї–Њ–Љ–њ–Њ–љ–µ–љ—В—Л Arenadata Platform¬ї, вАФ –њ–Њ—П—Б–љ–Є–ї –і–Њ–Ї–ї–∞–і—З–Є–Ї. –†–µ—И–µ–љ–Є–µ –њ–Њ–і–і–µ—А–ґ–Є–≤–∞–µ—В Arenadata Cluster Manager, —З—В–Њ –Њ–±–µ—Б–њ–µ—З–Є–≤–∞–µ—В –±–Њ–ї–µ–µ —Г–і–Њ–±–љ–Њ–µ –Є –±—Л—Б—В—А–Њ–µ —А–∞–Ј–≤–µ—А—В—Л–≤–∞–љ–Є–µ Luxms BI –≤ –Ї–ї–∞—Б—В–µ—А–љ–Њ–є –Ї–Њ–љ—Д–Є–≥—Г—А–∞—Ж–Є–Є. –Я—А–µ–і—Г—Б–Љ–Њ—В—А–µ–љ–∞ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М —А–∞—Б–њ—А–µ–і–µ–ї—П—В—М —Б–µ—А–≤–Є—Б—Л Luxms BI –њ–Њ –љ–µ—Б–Ї–Њ–ї—М–Ї–Є–Љ —Б–µ—А–≤–µ—А–∞–Љ, —З—В–Њ –њ–Њ–Ј–≤–Њ–ї—П–µ—В —В–Њ–љ–Ї–Њ –љ–∞—Б—В—А–∞–Є–≤–∞—В—М –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М —Б–Є—Б—В–µ–Љ—Л –њ–Њ–і –Ј–∞–і–∞—З–Є –Ј–∞–Ї–∞–Ј—З–Є–Ї–∞.
–Ф–ї—П —А–µ—И–µ–љ–Є—П ETL-–Ј–∞–і–∞—З –Ф–Љ–Є—В—А–Є–є –Ф–Њ—А–Њ—Д–µ–µ–≤ –њ—А–µ–і–ї–Њ–ґ–Є–ї –Є–љ—Б—В—А—Г–Љ–µ–љ—В Luxms Data Boring, –Ї–Њ—В–Њ—А—Л–є –њ–Њ–Љ–Њ–≥–∞–µ—В –Є–љ–ґ–µ–љ–µ—А–∞–Љ –Є –∞–љ–∞–ї–Є—В–Є–Ї–∞–Љ –≥–Њ—В–Њ–≤–Є—В—М –і–∞–љ–љ—Л–µ –і–ї—П —Н—Д—Д–µ–Ї—В–Є–≤–љ–Њ–є —Б–Ї–Њ—А–Њ—Б—В–љ–Њ–є –≤–Є–Ј—Г–∞–ї–Є–Ј–∞—Ж–Є–Є –≤ Luxms BI, –Ї–Њ–≥–і–∞ –≤–Є—В—А–Є–љ—Л DWH –љ–µ—Г–і–Њ–±–љ—Л. –Ю–љ –њ–Њ–љ–∞–і–Њ–±–Є—В—Б—П, –µ—Б–ї–Є —Е—А–∞–љ–Є–ї–Є—Й–µ –Љ–µ–і–ї–µ–љ–љ–Њ–µ, –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є –Љ–љ–Њ–≥–Њ –Є –і–ї—П –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П —Б–ї–Њ–ґ–љ–Њ–є –Њ–±—А–∞–±–Њ—В–Ї–Є –і–∞–љ–љ—Л—Е –љ–µ —Е–≤–∞—В–∞–µ—В —А–µ—Б—Г—А—Б–Њ–≤ –Є–ї–Є –љ–µ—В –ґ–µ–ї–∞–љ–Є—П –љ–∞–≥—А—Г–ґ–∞—В—М —Е—А–∞–љ–Є–ї–Є—Й–µ –Ј–∞–њ—А–Њ—Б–∞–Љ–Є –Є–Ј BI. ¬Ђ–Ш–љ—В–µ—А—Д–µ–є—Б –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—П –Љ—Л —Б–і–µ–ї–∞–ї–Є —В–∞–Ї, —З—В–Њ–±—Л –Њ–љ –±—Л–ї –њ–Њ–љ—П—В–µ–љ –і–∞–ґ–µ –љ–µ —Б–∞–Љ—Л–Љ –њ–Њ–і–≥–Њ—В–Њ–≤–ї–µ–љ–љ—Л–Љ –і–∞—В–∞-–Є–љ–ґ–µ–љ–µ—А–∞–Љ. –Э–∞–њ—А–Є–Љ–µ—А, –љ–∞—И–Є –љ–Њ–≤—Л–µ —Б–Њ—В—А—Г–і–љ–Є–Ї–Є вАФ –≤—З–µ—А–∞—И–љ–Є–µ —Б—В—Г–і–µ–љ—В—Л –±–µ–Ј –Њ—Б–Њ–±–Њ–≥–Њ –Њ–њ—Л—В–∞ вАФ –Њ—З–µ–љ—М –±—Л—Б—В—А–Њ –Њ—Б–≤–∞–Є–≤–∞—О—В Luxms Data Boring –Є –≤—Л–њ–Њ–ї–љ—П—О—В —Б–ї–Њ–ґ–љ—Л–µ –Ј–∞–і–∞—З–Є. –Ф–µ–ї–∞—О—В –Ї–∞–Ї–Є–µ-—В–Њ —Н–Ї–Ј–Њ—В–Є—З–µ—Б–Ї–Є–µ —И—В—Г–Ї–Є, –љ–∞–њ—А–Є–Љ–µ—А, —Б—В—Л–Ї—Г—О—В—Б—П —Б –Ї–∞–љ–∞–ї–∞–Љ–Є –≤ ¬Ђ–Ґ–µ–ї–µ–≥—А–∞–Љ¬ї –Є–ї–Є –≤—Л—В–∞—Б–Ї–Є–≤–∞—О—В –Ї–Њ—В–Є—А–Њ–≤–Ї–Є –∞–Ї—Ж–Є–є –Є–Ј html-—Б—В—А–∞–љ–Є—Ж, —В–Њ –µ—Б—В—М –Є—Б–њ–Њ–ї—М–Ј—Г—О—В –Є–љ—Б—В—А—Г–Љ–µ–љ—В –љ–µ—Б—В–∞–љ–і–∞—А—В–љ–Њ¬ї, вАФ –њ–Њ—П—Б–љ–Є–ї –Ф–Љ–Є—В—А–Є–є –Ф–Њ—А–Њ—Д–µ–µ–≤.
–Ъ–∞–Ї–∞—П –њ–Њ–ї—М–Ј–∞ –Њ—В –Ї–Њ–љ—В–∞–Ї—В-—Ж–µ–љ—В—А–∞
–Х—Б–ї–Є —Г –Ї–Њ–Љ–њ–∞–љ–Є–Є –µ—Б—В—М —Б–≤–Њ–є —Б–Њ–±—Б—В–≤–µ–љ–љ—Л–є –Ї–Њ–љ—В–∞–Ї—В-—Ж–µ–љ—В—А, —Н—В–Њ –љ—Г–ґ–љ–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М, —З—В–Њ –Є –њ—А–Њ–Є–Ј–Њ—И–ї–Њ –≤ –Њ—А–≥–∞–љ–Є–Ј–∞—Ж–Є–Є, –Ї–Њ—В–Њ—А—Г—О –њ—А–µ–і—Б—В–∞–≤–ї—П–ї –°—В–∞–љ–Є—Б–ї–∞–≤ –Ы—П—Е–Њ–≤–µ—Ж–Ї–Є–є, –Ј–∞–Љ–µ—Б—В–Є—В–µ–ї—М –≥–µ–љ–µ—А–∞–ї—М–љ–Њ–≥–Њ –і–Є—А–µ–Ї—В–Њ—А–∞ ¬Ђ–Р–Ї—В–Є–≤–С–Є–Ј–љ–µ—Б–Ъ–Њ–љ—Б–∞–ї—В¬ї (–≤—Е–Њ–і–Є—В –≤ –≥—А—Г–њ–њ—Г ¬Ђ–°–±–µ—А¬ї). –Э–∞ –Њ—Б–љ–Њ–≤–µ –і–∞–љ–љ—Л—Е –Є–Ј –Ї–Њ–љ—В–∞–Ї—В-—Ж–µ–љ—В—А–∞ –Ј–і–µ—Б—М —А–∞–Ј—А–∞–±–Њ—В–∞–ї–Є –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –њ—А–Њ–і—Г–Ї—В–Њ–≤ —А–µ—З–µ–≤–Њ–є –∞–љ–∞–ї–Є—В–Є–Ї–Є, –Ї–Њ—В–Њ—А—Г—О –љ–µ —В–Њ–ї—М–Ї–Њ –њ—А–µ–і–ї–∞–≥–∞—О—В –Ј–∞–Ї–∞–Ј—З–Є–Ї–∞–Љ, –љ–Њ –Є –Є—Б–њ–Њ–ї—М–Ј—Г—О—В —Б–∞–Љ–Є. ¬Ђ–Ь—Л –≤—Л–≤–Њ–і–Є–Љ –љ–∞ —А—Л–љ–Њ–Ї —В–Њ–ї—М–Ї–Њ —В–µ —А–µ—И–µ–љ–Є—П, –Ї–Њ—В–Њ—А—Л–µ –њ–Њ–њ—А–Њ–±–Њ–≤–∞–ї–Є –Є –Њ–±–Ї–∞—В–∞–ї–Є —Б–∞–Љ–Є. –Ш—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ —А–µ—З–µ–≤–Њ–є –∞–љ–∞–ї–Є—В–Є–Ї–Є –њ–Њ–Љ–Њ–≥–ї–Њ –љ–∞–Љ —Г–≤–Є–і–µ—В—М —В—Г —З–∞—Б—В—М –∞–є—Б–±–µ—А–≥–∞, –Ї–Њ—В–Њ—А–∞—П –Њ–±—Л—З–љ–Њ —Б–Ї—А—Л—В–∞ –њ–Њ–і –≤–Њ–і–Њ–є. –° –µ–µ –њ–Њ–Љ–Њ—Й—М—О –љ–∞–Љ —Г–і–∞–ї–Њ—Б—М –Њ–њ—В–Є–Љ–Є–Ј–Є—А–Њ–≤–∞—В—М –љ–µ–Ї–Њ—В–Њ—А—Л–µ –±–Є–Ј–љ–µ—Б-–њ—А–Њ—Ж–µ—Б—Б—Л¬ї, вАФ —А–∞—Б—Б–Ї–∞–Ј–∞–ї –і–Њ–Ї–ї–∞–і—З–Є–Ї.
–Ъ–∞–Ї –Є –Њ —З–µ–Љ —Б–Њ—В—А—Г–і–љ–Є–Ї–Є –≥–Њ–≤–Њ—А—П—В —Б –Ї–ї–Є–µ–љ—В–∞–Љ–Є? –°–ї–µ–і—Г—О—В –ї–Є –Њ–љ–Є —Б–Ї—А–Є–њ—В–∞–Љ –Є —Б—В–∞–љ–і–∞—А—В–∞–Љ? –Ъ–∞–Ї–Њ–≤—Л —В–Њ—З–Ї–Є —А–Њ—Б—В–∞ –≤ –і–Є–∞–ї–Њ–≥–∞—Е —Б–Њ—В—А—Г–і–љ–Є–Ї–Њ–≤ —Б –Ї–ї–Є–µ–љ—В–∞–Љ–Є? –Ъ–∞–Ї –њ–Њ–≤—Л—Б–Є—В—М –Є—Е —Н—Д—Д–µ–Ї—В–Є–≤–љ–Њ—Б—В—М –Є –Ї–Њ–љ–≤–µ—А—Б–Є–Њ–љ–љ–Њ—Б—В—М? –Т –Ј–≤–Њ–љ–Ї–∞—Е —Б–Ї—А—Л—В—Л —В—А–µ–љ–і—Л –Є –Є–љ—Б–∞–є—В—Л, –Ї–Њ—В–Њ—А—Л–µ –Љ–Њ–ґ–љ–Њ –љ–∞–є—В–Є –Є –Њ—Ж–µ–љ–Є—В—М –њ—А–Њ–±–ї–µ–Љ—Л –±–Є–Ј–љ–µ—Б–∞, –њ—А–µ–і–≤–Њ—Б—Е–Є—В–Є—В—М –Њ–ґ–Є–і–∞–љ–Є—П –Ї–ї–Є–µ–љ—В–Њ–≤.
–Т —А–∞–Љ–Ї–∞—Е —А–∞–Ј–≤–Є—В–Є—П —А–µ—И–µ–љ–Є—П –њ–Њ —А–µ—З–µ–≤–Њ–є –∞–љ–∞–ї–Є—В–Є–Ї–µ –Ј–і–µ—Б—М –Ј–∞–љ–Є–Љ–∞—О—В—Б—П –і–Є–∞—А–Є–Ј–∞—Ж–Є–µ–є, —В–Њ –µ—Б—В—М —А–∞–Ј–і–µ–ї–µ–љ–Є–µ–Љ –≤—Е–Њ–і—П—Й–µ–≥–Њ –∞—Г–і–Є–Њ–њ–Њ—В–Њ–Ї–∞ –љ–∞ –Њ–і–љ–Њ—А–Њ–і–љ—Л–µ —Б–µ–≥–Љ–µ–љ—В—Л –≤ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤–Є–Є —Б –њ—А–Є–љ–∞–і–ї–µ–ґ–љ–Њ—Б—В—М—О –∞—Г–і–Є–Њ–њ–Њ—В–Њ–Ї–∞ —В–Њ–Љ—Г –Є–ї–Є –Є–љ–Њ–Љ—Г –≥–Њ–≤–Њ—А—П—Й–µ–Љ—Г, –љ–µ —В–Њ–ї—М–Ї–Њ —Б—В–µ—А–µ–Њ, –љ–Њ –Є –Љ–Њ–љ–Њ–Ј–∞–њ–Є—Б–µ–є, –Ї–Њ—В–Њ—А—Л–µ —В—П–ґ–µ–ї–µ–µ –њ–Њ–і–і–∞—О—В—Б—П –Њ–±—А–∞–±–Њ—В–Ї–µ.
–Э–∞ –Њ—Б–љ–Њ–≤–µ –њ–Њ–ї—Г—З–µ–љ–љ—Л—Е –і–∞–љ–љ—Л—Е –Ї–Њ–Љ–њ–∞–љ–Є—П —Б—В—А–Њ–Є—В –Љ–Њ–і–µ–ї—М –≤—Л–≥–Њ—А–∞–љ–Є—П –Њ–њ–µ—А–∞—В–Њ—А–Њ–≤, –Љ–Њ–і–µ–ї—М –Њ–њ—А–µ–і–µ–ї–µ–љ–Є—П —Н–Љ–Њ—Ж–Є–є. –Ф–µ–є—Б—В–≤–Є–µ –њ–Њ—Б–ї–µ–і–љ–µ–є –°—В–∞–љ–Є—Б–ї–∞–≤ –Ы—П—Е–Њ–≤–µ—Ж–Ї–Є–є –њ—А–Њ–і–µ–Љ–Њ–љ—Б—В—А–Є—А–Њ–≤–∞–ї –љ–∞ –њ—А–∞–Ї—В–Є–Ї–µ, –Ј–∞–њ—Г—Б—В–Є–≤ –∞—Г–і–Є–Њ–Ј–∞–њ–Є—Б—М —А–µ–∞–ї—М–љ–Њ–≥–Њ –і–Є–∞–ї–Њ–≥–∞. –Ю–њ–µ—А–∞—В–Њ—А –≤–Є–і–Є—В, –Ї–∞–Ї–∞—П —Н–Љ–Њ—Ж–Є—П –њ—А–µ–Њ–±–ї–∞–і–∞–µ—В —Г —А–µ—Б–њ–Њ–љ–і–µ–љ—В–∞ –Є –њ–Њ–ї—Г—З–∞–µ—В –њ–Њ–і—Б–Ї–∞–Ј–Ї–Є –њ–Њ –і–∞–ї—М–љ–µ–є—И–µ–Љ—Г —Е–Њ–і—Г —А–∞–Ј–≥–Њ–≤–Њ—А–∞. ¬Ђ–§–∞–Ї—В–Є—З–µ—Б–Ї–Є, —Н—В–Њ –њ–µ—А—Б–Њ–љ–∞–ї—М–љ—Л–є –∞—Б—Б–Є—Б—В–µ–љ—В –Њ–њ–µ—А–∞—В–Њ—А–∞, –Ї–Њ—В–Њ—А—Л–є –њ–Њ–Љ–Њ–ґ–µ—В –µ–Љ—Г –≤–µ—Б—В–Є –і–Є–∞–ї–Њ–≥¬ї, вАФ –і–Њ–±–∞–≤–Є–ї –і–Њ–Ї–ї–∞–і—З–Є–Ї. –°–∞–Љ–Є –і–∞–љ–љ—Л–µ —А–∞–Ј–Љ–µ—З–∞—О—В—Б—П —В–∞–Ї–ґ–µ —Б –њ–Њ–Љ–Њ—Й—М—О —Б–Њ–±—Б—В–≤–µ–љ–љ–Њ–≥–Њ —А–µ—И–µ–љ–Є—П вАФ Elementary.
–Ф–ї—П HR-–Њ—В–і–µ–ї–∞ –Ї–Њ–Љ–њ–∞–љ–Є—П –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В —Б–µ—А–≤–Є—Б –≥–Њ–ї–Њ—Б–Њ–≤–Њ–≥–Њ —Б–Ї—А–Є–љ–Є–љ–≥–∞ вАФ –Њ–љ –њ–Њ–Љ–Њ–≥–∞–µ—В –љ–∞–±–Є—А–∞—В—М –ї—О–і–µ–є –љ–∞ –Љ–∞—Б—Б–Њ–≤—Л–µ, —В–Є–њ–Њ–≤—Л–µ –≤–∞–Ї–∞–љ—Б–Є–Є. –†–Њ–±–Њ—В –њ–Њ–Ј–≤–Њ–љ–Є—В –Є –њ—А–Њ–≤–µ–і–µ—В –љ–µ–±–Њ–ї—М—И–Њ–є –і–Є–∞–ї–Њ–≥, —Б–Љ–Њ–ґ–µ—В –Њ—В–≤–µ—В–Є—В—М –љ–∞ –њ—А–Њ—Б—В—Л–µ –≤–Њ–њ—А–Њ—Б—Л, –љ–∞–њ—А–Є–Љ–µ—А, –≤ —З–µ–Љ –Ј–∞–Ї–ї—О—З–∞—О—В—Б—П —В—А–µ–±–Њ–≤–∞–љ–Є—П –Ї –Ї–∞–љ–і–Є–і–∞—В—Г –Є–ї–Є –Ї–∞–Ї–∞—П –Ј–∞—А–њ–ї–∞—В–∞ –њ—А–µ–і–њ–Њ–ї–∞–≥–∞–µ—В—Б—П. –Э–∞–є–Љ–Њ–Љ –і–µ–ї–Њ –љ–µ –Њ–≥—А–∞–љ–Є—З–Є–≤–∞–µ—В—Б—П. –≠—В–Њ—В –ґ–µ —Б–µ—А–≤–Є—Б –Љ–Њ–ґ–љ–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –і–ї—П —А–µ—И–µ–љ–Є—П —Б–∞–Љ—Л—Е —А–∞–Ј–љ—Л—Е –Ј–∞–і–∞—З, –љ–∞–њ—А–Є–Љ–µ—А, –і–ї—П —Д—А–Њ–і-–∞–љ–∞–ї–Є—В–Є–Ї–Є –њ–Њ –Ї—А–µ–і–Є—В–∞–Љ, –і–ї—П –Ј–≤–Њ–љ–Ї–Њ–≤ –і–Њ–ї–ґ–љ–Є–Ї–∞–Љ –Є –і–∞–ґ–µ –і–ї—П –њ—А–µ–і—Б–Ї–∞–Ј–∞–љ–Є—П –ґ–∞–ї–Њ–± –Ї–ї–Є–µ–љ—В–Њ–≤ –Ї–Њ–ї–ї-—Ж–µ–љ—В—А–∞.
–Ґ—А–µ—В–Є–є –њ—А–Њ–і—Г–Ї—В, –њ—А–µ–і—Б—В–∞–≤–ї–µ–љ–љ—Л–є –љ–∞ –Ї–Њ–љ—Д–µ—А–µ–љ—Ж–Є–Є, –њ–Њ–Љ–Њ–≥–∞–µ—В –Ј–∞—Й–Є—В–Є—В—М—Б—П –Њ—В –Љ–Њ—И–µ–љ–љ–Є–Ї–Њ–≤. –£—З–Є—В—Л–≤–∞—П, —З—В–Њ –Ї–∞–ґ–і—Л–є –і–µ—Б—П—В—Л–є –Ј–≤–Њ–љ–Њ–Ї –њ–Њ—Б—В—Г–њ–∞–µ—В –Њ—В –љ–µ–і–Њ–±—А–Њ—Б–Њ–≤–µ—Б—В–љ—Л—Е –ї—О–і–µ–є, –Ј–∞–і–∞—З–∞ –Њ—З–µ–љ—М –∞–Ї—В—Г–∞–ї—М–љ–∞—П.
–Ч–∞—Й–Є—В–∞ –Њ—В –Љ–Њ—И–µ–љ–љ–Є–Ї–Њ–≤ вАФ –љ–Њ–≤–∞—П ESG-–њ–Њ–≤–µ—Б—В–Ї–∞

–Т—Е–Њ–і—П—Й–Є–µ –Ј–≤–Њ–љ–Ї–Є –≤ —А–µ–∞–ї—М–љ–Њ–Љ –≤—А–µ–Љ–µ–љ–Є –∞–љ–∞–ї–Є–Ј–Є—А—Г—О—В—Б—П –Є—Б–Ї—Г—Б—Б—В–≤–µ–љ–љ—Л–Љ –Є–љ—В–µ–ї–ї–µ–Ї—В–Њ–Љ, –Ї–Њ—В–Њ—А—Л–є –Њ–±—Г—З–µ–љ –≤—Л—П–≤–ї—П—В—М –Љ–Њ—И–µ–љ–љ–Є—З–µ—Б–Ї–Є–µ —Б—Е–µ–Љ—Л. –Х—Б–ї–Є –≤ —А–∞–Ј–≥–Њ–≤–Њ—А–µ –Њ–±–љ–∞—А—Г–ґ–µ–љ—Л –њ—А–Є–Ј–љ–∞–Ї–Є –Љ–Њ—И–µ–љ–љ–Є—З–µ—Б—В–≤–∞, —В–Њ –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—М, –њ–Њ–і–Ї–ї—О—З–Є–≤—И–Є–є —Б–µ—А–≤–Є—Б, —Г—Б–ї—Л—И–Є—В —Б–њ–µ—Ж–Є–∞–ї—М–љ–Њ–µ –Ј–≤—Г–Ї–Њ–≤–Њ–µ —Б–Њ–Њ–±—Й–µ–љ–Є–µ. –У–Њ–ї–Њ—Б–Њ–≤–Њ–є –њ–Њ—В–Њ–Ї –њ—А–Є —Н—В–Њ–Љ –љ–µ —Б–Њ—Е—А–∞–љ—П–µ—В—Б—П, –њ–Њ—Н—В–Њ–Љ—Г –Љ–Њ–ґ–љ–Њ –љ–µ –±–µ—Б–њ–Њ–Ї–Њ–Є—В—М—Б—П –Њ –њ—А–Є–≤–∞—В–љ–Њ—Б—В–Є. ¬Ђ–ѓ –µ—Й–µ –љ–Є —Г –Ї–Њ–≥–Њ –љ–µ –≤–Є–і–µ–ї –њ–Њ–і–Њ–±–љ–Њ–≥–Њ —А–µ—И–µ–љ–Є—П¬ї, вАФ –≥–Њ–≤–Њ—А–Є—В –°—В–∞–љ–Є—Б–ї–∞–≤ –Ы—П—Е–Њ–≤–µ—Ж–Ї–Є–є.
–Ш—Б–Ї—Г—Б—Б—В–≤–µ–љ–љ—Л–є –Є–љ—В–µ–ї–ї–µ–Ї—В –љ–µ —Б–і–∞–µ—В—Б—П
–Ґ–µ–Љ–µ –Є—Б–Ї—Г—Б—Б—В–≤–µ–љ–љ–Њ–≥–Њ –Є–љ—В–µ–ї–ї–µ–Ї—В–∞ (–Ш–Ш) —А–µ—И–Є–ї –њ–Њ—Б–≤—П—В–Є—В—М —Б–≤–Њ–µ –≤—Л—Б—В—Г–њ–ї–µ–љ–Є–µ –°–µ—А–≥–µ–є –Р–ї–µ—И–Ї–Є–љ, –≥–ї–∞–≤–∞ –і–µ–њ–∞—А—В–∞–Љ–µ–љ—В–∞ Data Science –°–Ю–У–Р–Ч. ¬Ђ–Т 2020 –≥–Њ–і—Г –Њ–±—К–µ–Љ —А—Л–љ–Ї–∞ –Ш–Ш –≤ –†–Њ—Б—Б–Є–Є —Б–Њ—Б—В–∞–≤–ї—П–ї 291 –Љ–ї–љ –і–Њ–ї–ї–∞—А–Њ–≤ –Є —Б–µ–є—З–∞—Б, –љ–µ—Б–Љ–Њ—В—А—П –љ–∞ –≤—Б–µ —Б–Њ–±—Л—В–Є—П, –Њ–љ –њ—А–Є–љ–Њ—Б–Є—В —Ж–µ–љ–љ–Њ—Б—В—М –Ї–Њ–Љ–њ–∞–љ–Є—П–Љ¬ї, вАФ –≥–Њ–≤–Њ—А–Є—В –Њ–љ.
–Т –Њ–±–ї–∞—Б—В–Є —Б—В—А–∞—Е–Њ–≤–∞–љ–Є—П 30% –Ї–Њ–Љ–њ–∞–љ–Є–є –њ—А–Є–Љ–µ–љ—П—О—В –Ш–Ш –≤ —В–µ—Е –Є–ї–Є –Є–љ—Л—Е –±–Є–Ј–љ–µ—Б-–њ—А–Њ—Ж–µ—Б—Б–∞—Е (–њ—А–Њ–≤–µ–і–µ–љ–Є–µ —Б–Ї–Њ—А–Є–љ–≥–∞ –њ—А–Є –њ—А–µ–і—Б—В—А–∞—Е–Њ–≤–Њ–є –њ—А–Њ–≤–µ—А–Ї–µ, –∞–љ–∞–ї–Є—В–Є—З–µ—Б–Ї–Њ–µ –≤—Л—П–≤–ї–µ–љ–Є–µ –Љ–Њ—И–µ–љ–љ–Є—З–µ—Б–Ї–Є—Е —Г–±—Л—В–Ї–Њ–≤ –Є —В–∞–Ї –і–∞–ї–µ–µ), –њ—А–Є —Н—В–Њ–Љ 25% –Ї–ї–Є–µ–љ—В–Њ–≤ —Г–ґ–µ –≥–Њ—В–Њ–≤—Л –њ–Њ–ї–љ–Њ—Б—В—М—О –њ–µ—А–µ–є—В–Є –љ–∞ —Ж–Є—Д—А–Њ–≤–Њ–µ —Б—В—А–∞—Е–Њ–≤–∞–љ–Є–µ.
–Ш—Б–Ї—Г—Б—Б—В–≤–µ–љ–љ—Л–є –Є–љ—В–µ–ї–ї–µ–Ї—В вАУ –Ї–ї—О—З–µ–≤–Њ–є —Н–ї–µ–Љ–µ–љ—В —Ж–Є—Д—А–Њ–≤–Њ–є —В—А–∞–љ—Б—Д–Њ—А–Љ–∞—Ж–Є–Є
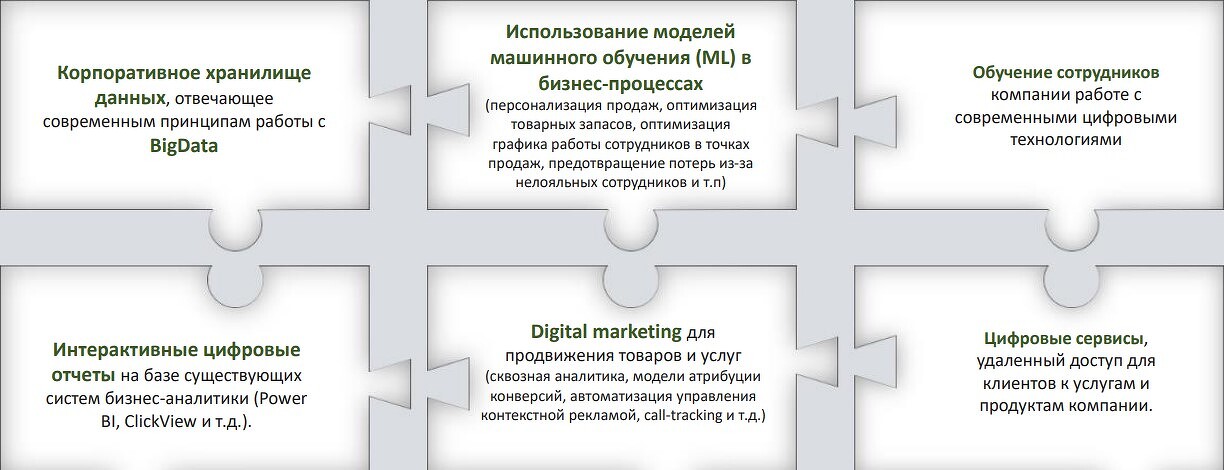
–Ю–і–љ–Њ–є –Є–Ј –≤–∞–ґ–љ—Л—Е –Ј–∞–і–∞—З —П–≤–ї—П–µ—В—Б—П –њ—А–Њ–≥–љ–Њ–Ј–Є—А–Њ–≤–∞–љ–Є–µ —Г—Е–Њ–і–∞ –Ї–ї–Є–µ–љ—В–∞ –Є –µ–≥–Њ —Г–і–µ—А–ґ–∞–љ–Є–µ –Њ—В —В–∞–Ї–Њ–≥–Њ —И–∞–≥–∞. –Я—А–Є –њ—А–Є–Љ–µ–љ–µ–љ–Є–Є –Ш–Ш –≤ –Ї—А–Њ—Б—Б-–њ—А–Њ–і–∞–ґ–∞—Е, 40% –Ї–ї–Є–µ–љ—В–Њ–≤ –Є–Ј –Њ—В–Њ–±—А–∞–љ–љ—Л—Е –Љ–∞—И–Є–љ–Њ–є –±—Л–ї–Є –≥–Њ—В–Њ–≤—Л –Ї—Г–њ–Є—В—М –њ—А–Њ–і—Г–Ї—В—Л –і–Њ–±—А–Њ–≤–Њ–ї—М–љ–Њ–≥–Њ —Б—В—А–∞—Е–Њ–≤–∞–љ–Є—П –≤ –±–ї–Є–ґ–∞–є—И–µ–µ –≤—А–µ–Љ—П. –Р–ї–≥–Њ—А–Є—В–Љ—Л –Њ—В–±—А–∞—Б—Л–≤–∞–ї–Є 98% —В–µ—Е, –Ї—В–Њ –Њ–Ї–∞–Ј–∞–ї—Б—П –љ–µ –Ј–∞–Є–љ—В–µ—А–µ—Б–Њ–≤–∞–љ –≤ –њ–Њ–Ї—Г–њ–Ї–µ, —В–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ —Б–љ–Є–ґ–∞—П —В—А—Г–і–Њ–Ј–∞—В—А–∞—В—Л —Б–µ—В–Є –љ–∞ –Ї—А–Њ—Б—Б-–њ—А–Њ–і–∞–ґ–Є –≤ 30 —А–∞–Ј.
–І—В–Њ–±—Л —Г—Б–њ–µ—И–љ–Њ –≤–љ–µ–і—А–Є—В—М –Ш–Ш, –і–Њ–Ї–ї–∞–і—З–Є–Ї –њ—А–µ–і–ї–Њ–ґ–Є–ї –њ—А–Є–і–µ—А–ґ–Є–≤–∞—В—М—Б—П –љ–µ—Б–Ї–Њ–ї—М–Ї–Є—Е –њ—А–Є–љ—Ж–Є–њ–Њ–≤. –Я–Њ –µ–≥–Њ –Љ–љ–µ–љ–Є—О, –≤–љ–µ–і—А–µ–љ–Є–µ —Б–ї–µ–і—Г–µ—В –љ–∞—З–Є–љ–∞—В—М —Б –±–Є–Ј–љ–µ—Б-–њ—А–Њ—Ж–µ—Б—Б–∞, –≥–і–µ –Њ–љ —Б–Љ–Њ–ґ–µ—В –њ—А–Є–љ–µ—Б—В–Є –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–Њ –±—Л—Б—В—А—Л–є —Н—Д—Д–µ–Ї—В. –†–µ–∞–ї—М–љ–∞—П –±–Є–Ј–љ–µ—Б-–≤—Л–≥–Њ–і–∞ —Б –њ–Њ–љ—П—В–љ—Л–Љ —Б—А–Њ–Ї–Њ–Љ –Њ–Ї—Г–њ–∞–µ–Љ–Њ—Б—В–Є –њ–Њ–≤—Л—И–∞–µ—В –і–Њ–≤–µ—А–Є–µ –Ї –Ш–Ш –≤ –Ї–Њ–Љ–њ–∞–љ–Є–Є. –Т –љ–∞—З–∞–ї–µ –≤–љ–µ–і—А–µ–љ–Є—П –ї—Г—З—И–µ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –ї–µ–≥–Ї–Њ –Є–љ—В–µ—А–њ—А–µ—В–Є—А—Г–µ–Љ—Л–µ –Љ–Њ–і–µ–ї–Є, –Ї –њ—А–Є–Љ–µ—А—Г, –ї–Њ–≥–Є—Б—В–Є—З–µ—Б–Ї—Г—О —А–µ–≥—А–µ—Б—Б–Є—О. –≠—В–Њ —Б–љ–Є–Ј–Є—В –Љ–Њ–і–µ–ї—М–љ—Л–є —А–Є—Б–Ї, —В–∞–Ї –Ї–∞–Ї –њ–Њ–Ј–≤–Њ–ї–Є—В –љ–∞ —А–∞–љ–љ–µ–є —Б—В–∞–і–Є–Є –њ—А–Њ–≤–µ—А–Є—В—М –њ—А–∞–≤–Є–ї—М–љ–Њ—Б—В—М –Њ—Ж–µ–љ–Ї–Є –Љ–Њ–і–µ–ї—М—О —Д–∞–Ї—В–Њ—А–Њ–≤, –≤–ї–Є—П—О—Й–Є—Е –љ–∞ —Ж–µ–ї–µ–≤–Њ–є –њ–Њ–Ї–∞–Ј–∞—В–µ–ї—М.
–Х—Б–ї–Є –≥–Њ–≤–Њ—А–Є—В—М –Њ –Љ–Њ–і–µ–ї—П—Е, —В–Њ –°–µ—А–≥–µ–є –Р–ї–µ—И–Ї–Є–љ —А–µ–Ї–Њ–Љ–µ–љ–і—Г–µ—В —Б—В—А–Њ–Є—В—М –±—Л—Б—В—А—Л–µ –њ—А–Њ—В–Њ—В–Є–њ—Л –Љ–Њ–і–µ–ї–µ–є –Є –љ–µ –±–Њ—П—В—М—Б—П –Њ—И–Є–±–Њ–Ї. –Т —Б—А–µ–і–љ–µ–Љ, –Є–Ј 10 –њ–Њ–і–≥–Њ—В–Њ–≤–ї–µ–љ–љ—Л—Е –Љ–Њ–і–µ–ї–µ–є ¬Ђ–≤–Ј–ї–µ—В–∞–µ—В¬ї —В–Њ–ї—М–Ї–Њ –Њ–і–љ–∞-–і–≤–µ. –Ъ—А–Њ–Љ–µ —В–Њ–≥–Њ, –љ—Г–ґ–љ–Њ –њ–Њ—Б—В–Њ—П–љ–љ–Њ –Њ—В—Б–ї–µ–ґ–Є–≤–∞—В—М –Ї–∞—З–µ—Б—В–≤–µ–љ–љ—Л–µ –Љ–µ—В—А–Є–Ї–Є –Є—Б–њ–Њ–ї—М–Ј—Г–µ–Љ—Л—Е –Љ–Њ–і–µ–ї–µ–є. –Ь–Њ–і–µ–ї–Є –Ш–Ш –љ–∞—Б—В—А–∞–Є–≤–∞—О—В—Б—П –љ–∞ —В–µ–Ї—Г—Й–Є–µ –Ј–љ–∞—З–µ–љ–Є—П –њ–∞—А–∞–Љ–µ—В—А–Њ–≤, –Ї –њ—А–Є–Љ–µ—А—Г, –љ–∞ —Г—А–Њ–≤–µ–љ—М –і–Њ—Е–Њ–і–∞. –Я—А–Є —Б—Г—Й–µ—Б—В–≤–µ–љ–љ—Л—Е –Є–Ј–Љ–µ–љ–µ–љ–Є—П—Е —Н—В–Є—Е —Г—Б–ї–Њ–≤–Є–є –Ї–∞—З–µ—Б—В–≤–Њ –њ—А–Њ–≥–љ–Њ–Ј–∞ –Љ–Њ–і–µ–ї–Є –Љ–Њ–ґ–µ—В –Ї—А–Є—В–Є—З–љ–Њ —Б–љ–Є–Ј–Є—В—М—Б—П.
–Ю –љ–Њ–≤–Њ–є –Ї–Њ–љ—Ж–µ–њ—Ж–Є–Є –Љ–∞—И–Є–љ–љ–Њ–≥–Њ –Њ–±—Г—З–µ–љ–Є—П вАФ Reliable ML вАФ –њ—А–µ–і–ї–Њ–ґ–Є–ї–∞ –њ–Њ–≥–Њ–≤–Њ—А–Є—В—М –Ш—А–Є–љ–∞ –У–Њ–ї–Њ—Й–∞–њ–Њ–≤–∞, –≥–ї–∞–≤–∞ –і–µ–њ–∞—А—В–∞–Љ–µ–љ—В–∞ Data Science –Ї–Њ–Љ–њ–∞–љ–Є–Є ¬Ђ–Ы–µ–љ—В–∞¬ї. Reliable ML –њ–Њ–Љ–Њ–≥–∞–µ—В —Б–і–µ–ї–∞—В—М —В–∞–Ї, —З—В–Њ–±—Л —А–µ–Ј—Г–ї—М—В–∞—В —А–∞–±–Њ—В—Л data science –Є big data –Ї–Њ–Љ–∞–љ–і –±—Л–ї, –≤–Њ-–њ–µ—А–≤—Л—Е, –њ—А–Є–Љ–µ–љ–Є–Љ –≤ –±–Є–Ј–љ–µ—Б-–њ—А–Њ—Ж–µ—Б—Б–∞—Е –Ї–Њ–Љ–њ–∞–љ–Є–Є-–Ј–∞–Ї–∞–Ј—З–Є–Ї–∞, –∞ –≤–Њ-–≤—В–Њ—А—Л—Е, –њ—А–Є–љ–Њ—Б–Є–ї –±—Л –Ї–Њ–Љ–њ–∞–љ–Є–Є —Д–Є–љ–∞–љ—Б–Њ–≤—Г—О –њ–Њ–ї—М–Ј—Г. ¬Ђ–Э–∞–њ—А–∞–≤–ї–µ–љ–Є–µ –≤–Њ–Ј–љ–Є–Ї–ї–Њ –њ–Њ—В–Њ–Љ—Г, —З—В–Њ –Ј–∞ –њ–Њ—Б–ї–µ–і–љ–Є–є –і–µ—Б—П—В–Њ–Ї –ї–µ—В, –Њ—Б–Њ–±–µ–љ–љ–Њ –љ–∞ —Д–Њ–љ–µ —Е–∞–є–њ–∞, —Б–≤—П–Ј–∞–љ–љ–Њ–≥–Њ —Б –Љ–∞—И–Є–љ–љ—Л–Љ –Њ–±—Г—З–µ–љ–Є–µ–Љ, –Љ–љ–Њ–≥–Є–µ —А–∞–Ј—А–∞–±–∞—В—Л–≤–∞–µ–Љ—Л–µ –Љ–Њ–і–µ–ї–Є –Њ–Ї–∞–Ј—Л–≤–∞–ї–Є—Б—М –љ–µ–њ—А–Є–Љ–µ–љ–Є–Љ—Л –Є–ї–Є –њ—А–Є–љ–Њ—Б–Є–ї–Є –љ–µ —В–Њ—В —Н—Д—Д–µ–Ї—В, –Ї–Њ—В–Њ—А—Л–є –Њ–ґ–Є–і–∞–ї—Б—П. –Т—Б–µ –Њ—И–Є–±–Ї–Є, –Ї–Њ—В–Њ—А—Л–µ –±—Л–ї–Є —Б–Њ–±—А–∞–љ—Л, –њ–Њ—А–Њ–і–Є–ї–Є –љ–Њ–≤—Г—О –Ї–Њ–љ—Ж–µ–њ—Ж–Є—О¬ї, вАФ —А–∞—Б—Б–Ї–∞–Ј–∞–ї–∞ –Ш—А–Є–љ–∞ –У–Њ–ї–Њ—Й–∞–њ–Њ–≤–∞.
–Ґ–µ—Е–љ–Њ–ї–Њ–≥–Є—З–µ—Б–Ї–Є Reliable ML —Б–Њ—Б—В–Њ–Є—В –Є–Ј 3 –Ї—А—Г–њ–љ—Л—Е –±–ї–Њ–Ї–Њ–≤: –Є–љ—В–µ—А–њ—А–µ—В–Є—А—Г–µ–Љ–Њ—Б—В—М –Љ–Њ–і–µ–ї–µ–є –Љ–∞—И–Є–љ–љ–Њ–≥–Њ –Њ–±—Г—З–µ–љ–Є—П вАФ –ї–Њ–≥–Є–Ї–∞ –Љ–Њ–і–µ–ї–µ–є –і–Њ–ї–ґ–љ–∞ –±—Л—В—М –њ–Њ–љ—П—В–љ–∞ –Ї–Њ–љ–µ—З–љ–Њ–Љ—Г –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—О; –њ—А–Є—З–Є–љ–љ–Њ-—Б–ї–µ–і—Б—В–≤–µ–љ–љ—Л–є –∞–љ–∞–ї–Є–Ј ML –Є –і–Є–Ј–∞–є–љ —Б–Є—Б—В–µ–Љ—Л –Љ–∞—И–Є–љ–љ–Њ–≥–Њ –Њ–±—Г—З–µ–љ–Є—П –≤ —Ж–µ–ї–Њ–Љ.
–Т ¬Ђ–Ы–µ–љ—В–µ¬ї Reliable ML –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П –і–ї—П —В–Њ–≥–Њ, —З—В–Њ–±—Л –љ–∞–Є–ї—Г—З—И–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ –≤—Л–±–Є—А–∞—В—М –≥–µ–Њ–ї–Њ–Ї–∞—Ж–Є–Є –і–ї—П –Њ—В–Ї—А—Л–≤–∞–µ–Љ—Л—Е –Љ–∞–≥–∞–Ј–Є–љ–Њ–≤. –Я—А–Њ–≥–љ–Њ–Ј –≤—Л—А—Г—З–Ї–Є –і–ї—П –Ї–Њ–љ–Ї—А–µ—В–љ—Л—Е –ї–Њ–Ї–∞—Ж–Є–є вАФ –Њ—Б–љ–Њ–≤–∞ –±–Є–Ј–љ–µ—Б-–њ—А–Њ—Ж–µ—Б—Б–∞. –Ь–Њ–і–µ–ї—М –і–Њ–ї–ґ–љ–∞ —Г—З–Є—В—Л–≤–∞—В—М –Ї–ї—О—З–µ–≤—Л–µ —Д–∞–Ї—В–Њ—А—Л, —Б–њ–Њ—Б–Њ–±–љ—Л–µ –њ–Њ–≤–ї–Є—П—В—М –љ–∞ —Д–Є–љ–∞–љ—Б–Њ–≤—Г—О –≤—Л–≥–Њ–і—Г –Њ—В –Њ—В–Ї—А—Л—В–Є—П –Љ–∞–≥–∞–Ј–Є–љ–∞ –≤ –Ї—А–∞—В–Ї–Њ–Љ –Є –і–Њ–ї–≥–Њ—Б—А–Њ—З–љ–Њ–Љ –њ–µ—А–Є–Њ–і–∞—Е. –Ъ–∞–Ї –ґ–µ ML-–Љ–Њ–і–µ–ї–Є –≤—Б—В—А–Њ–Є—В—М—Б—П –≤ —В–µ–Ї—Г—Й—Г—О –Є–љ–Є—Ж–Є–∞—В–Є–≤—Г, —З—В–Њ–±—Л –њ—А–Є–љ–Њ—Б–Є—В—М –њ–Њ–ї—М–Ј—Г?
–§—А–µ–є–Љ–≤–Њ—А–Ї Reliable ML вАФ –Ї–∞–Ї–Њ–≤–∞ —Ж–µ–ї—М —А–µ—И–µ–љ–Є—П –Ј–∞–і–∞—З–Є —Б –њ–Њ–Љ–Њ—Й—М—О ML?
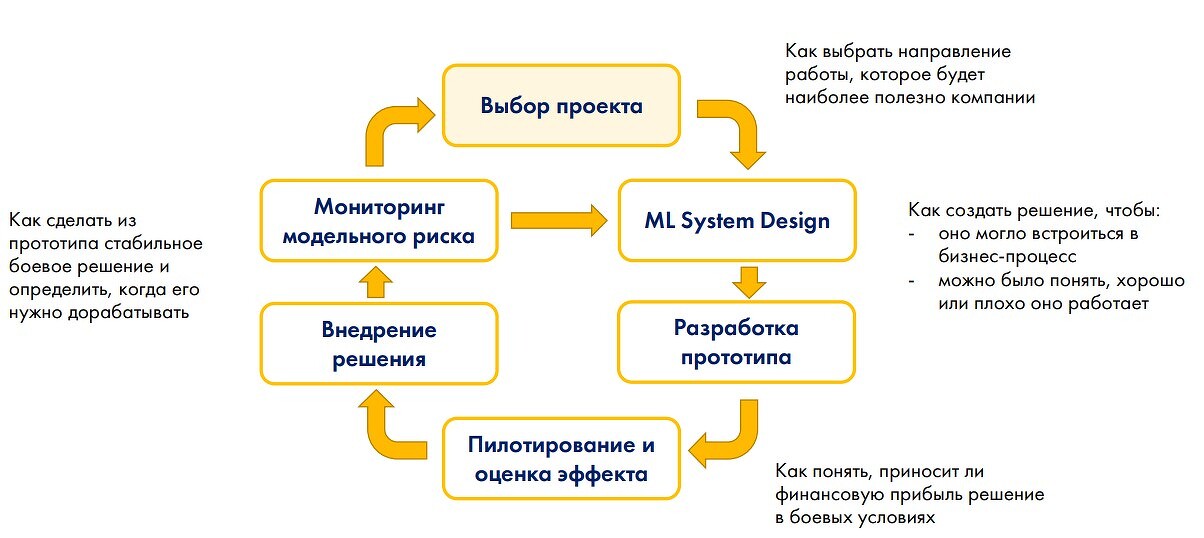
¬Ђ–Х—Б–ї–Є –≤ –љ–∞—З–∞–ї–µ –ї—О–±–Њ–є –Є–љ–Є—Ж–Є–∞—В–Є–≤—Л, —Б–≤—П–Ј–∞–љ–љ–Њ–є —Б –њ—А–Њ–і–≤–Є–љ—Г—В–Њ–є –∞–љ–∞–ї–Є—В–Є–Ї–Њ–є, —Б–њ—А–Њ—Б–Є—В—М —Г –Љ–∞—В–µ–Љ–∞—В–Є–Ї–Њ–≤, –і–∞—В–∞-—Б–∞–є–µ–љ—В–Є—Б—В–Њ–≤, –Ї–∞–Ї–Є–Љ –±—Г–і–µ—В —А–µ–Ј—Г–ї—М—В–∞—В –Є—Е —А–∞–±–Њ—В—Л, –Њ–љ–Є –Њ—В–≤–µ—В—П—В, —З—В–Њ —Н—В–Њ–≥–Њ –љ–Є–Ї—В–Њ –љ–µ –Ј–љ–∞–µ—В¬ї, вАФ –Њ–±—К—П—Б–љ—П–µ—В –і–Њ–Ї–ї–∞–і—З–Є—Ж–∞. –°—А–µ–і–Є –µ–µ —А–µ–Ї–Њ–Љ–µ–љ–і–∞—Ж–Є–є вАФ –Є–і—В–Є –Њ—В –њ—А–Њ—Б—В–Њ–≥–Њ –Ї —Б–ї–Њ–ґ–љ–Њ–Љ—Г –њ—А–Є —Б–Њ–Ј–і–∞–љ–Є–Є ML System Design, –њ—А–Є—З–µ–Љ —Г—Б–ї–Њ–ґ–љ–µ–љ–Є–µ –і–Њ–ї–ґ–љ–Њ –±—Л—В—М –њ–Њ—Б–ї–µ–і–Њ–≤–∞—В–µ–ї—М–љ—Л–Љ, –њ–Њ –Љ–µ—А–µ —А–Њ—Б—В–∞ –Ї–Њ–Љ–Љ–µ—А—З–µ—Б–Ї–Њ–≥–Њ —Н—Д—Д–µ–Ї—В–∞. –Э—Г–ґ–љ–Њ —Б–Њ–Ј–і–∞—В—М –±–∞–Ј–Є—Б –Є –Њ–њ—Л—В–љ—Л–Љ –њ—Г—В–µ–Љ –љ–∞–є—В–Є –≤—Б–µ –±–ї–Њ–Ї–Є –≤ –±–Є–Ј–љ–µ—Б-–њ—А–Њ—Ж–µ—Б—Б–µ, –Ї–Њ—В–Њ—А—Л–µ –Љ–Њ–≥—Г—В –Ї—А–Є—В–Є—З–µ—Б–Ї–Є –њ–Њ–≤–ї–Є—П—В—М –љ–∞ –і–Є–Ј–∞–є–љ —Б–Є—Б—В–µ–Љ—Л –Љ–∞—И–Є–љ–љ–Њ–≥–Њ –Њ–±—Г—З–µ–љ–Є—П, –∞ –њ–Њ—В–Њ–Љ —Б–Ї–Њ—А—А–µ–Ї—В–Є—А–Њ–≤–∞—В—М –±–Є–Ј–љ–µ—Б-—В—А–µ–±–Њ–≤–∞–љ–Є—П –Є –Ї—А–Є—Б—В–∞–ї–ї–Є–Ј–Њ–≤–∞—В—М –Љ–µ—В—А–Є–Ї–Є –Ї–∞—З–µ—Б—В–≤–∞, —Б –њ–Њ–Љ–Њ—Й—М—О –Ї–Њ—В–Њ—А–Њ–є –±—Г–і–µ—В –Њ—Ж–µ–љ–Є–≤–∞—В—М—Б—П –Ї–∞—З–µ—Б—В–≤–Њ —А–∞–±–Њ—В—Л –Љ–Њ–і–µ–ї–Є.
–Т ¬Ђ–Ы–µ–љ—В–µ¬ї –љ–∞—З–Є–љ–∞—О—В —Б –њ—А–Њ—Б—В–Њ–≥–Њ –∞–љ–∞–ї–Є—В–Є—З–µ—Б–Ї–Њ–≥–Њ —А–∞—Б—З–µ—В–∞ —Б —Г—З–µ—В–Њ–Љ —Н–Ї—Б–њ–µ—А—В–Є–Ј—Л –≤ –і–Њ–Љ–µ–љ–љ–Њ–є –Њ–±–ї–∞—Б—В–Є, –Ј–∞—В–µ–Љ –њ–µ—А–µ—Е–Њ–і—П—В –Ї –±–Њ–ї–µ–µ —В–Њ—З–љ–Њ–є –Њ—Ж–µ–љ–Ї–µ –Њ–ґ–Є–і–∞–µ–Љ–Њ–є –≤—Л—А—Г—З–Ї–Є –Ј–∞ —Б—З–µ—В —Г—З–µ—В–∞ –±–Њ–ї—М—И–µ–≥–Њ —З–Є—Б–ї–∞ –Ј–∞–≤–Є—Б–Є–Љ–Њ—Б—В–µ–є –Є –і–∞–љ–љ—Л—Е. –Ґ—А–µ—В–Є–є —Н—В–∞–њ вАФ –њ–µ—А–µ—Е–Њ–і –Њ—В —А–µ—В—А–Њ—Б–њ–µ–Ї—В–Є–≤–љ–Њ–є –Ї –њ—А–Њ–≥–љ–Њ–Ј–љ–Њ–є –∞–љ–∞–ї–Є—В–Є–Ї–µ (–Ї–∞–Ї –Є–Ј–Љ–µ–љ–Є—В—Б—П –≤—Л—А—Г—З–Ї–∞ –Љ–∞–≥–∞–Ј–Є–љ–∞, –µ—Б–ї–Є –Є–Ј–Љ–µ–љ–Є—В—М –Њ–њ—А–µ–і–µ–ї–µ–љ–љ—Л–µ –њ–∞—А–∞–Љ–µ—В—А—Л –≥–µ–Њ–ї–Њ–Ї–∞—Ж–Є–Є?). –І–µ—В–≤–µ—А—В—Л–є —Н—В–∞–њ вАФ –њ—А–µ–і–њ–Є—Б–∞—В–µ–ї—М–љ–∞—П –∞–љ–∞–ї–Є—В–Є–Ї–∞, –Њ—В–≤–µ—В –љ–∞ —В–Њ—В —Б–∞–Љ—Л–є –≤–Њ–њ—А–Њ—Б –Њ –љ–∞–Є–ї—Г—З—И–µ–є –ї–Њ–Ї–∞—Ж–Є–Є –і–ї—П –љ–Њ–≤–Њ–є —В–Њ—А–≥–Њ–≤–Њ–є —В–Њ—З–Ї–Є. –І–∞—Й–µ –≤—Б–µ–≥–Њ —Н—В–Њ –і–µ–ї–∞–µ—В—Б—П —Б –њ–Њ–Љ–Њ—Й—М—О —В–µ–њ–ї–Њ–≤—Л—Е –Ї–∞—А—В.
–£—Б—В—А–Њ–є—Б—В–≤–Њ –Є—Б–њ–Њ–ї—М–Ј—Г–µ–Љ–Њ–є –≥–µ–Њ–Љ–Њ–і–µ–ї–Є

–Ю—Ж–µ–љ–Є—В—М —Н—Д—Д–µ–Ї—В–Є–≤–љ–Њ—Б—В—М –њ–Њ–ї—Г—З–µ–љ–љ–Њ–є –Љ–Њ–і–µ–ї–Є —В–Њ–ґ–µ –љ–µ–њ—А–Њ—Б—В–Њ. –Я—А–Њ—Б—В–Њ–µ —Б—А–∞–≤–љ–µ–љ–Є–µ —Б—А–µ–і–љ–Є—Е –љ–µ —А–∞–±–Њ—В–∞–µ—В. –°–ї–Њ–ґ–љ–Њ –Њ—В–ї–Є—З–Є—В—М —Н—Д—Д–µ–Ї—В –Њ—В —Б–ї—Г—З–∞–є–љ–Њ—Б—В–Є, –≤–ї–Є—П–љ–Є—П –≤–љ–µ—И–љ–Є—Е —Д–∞–Ї—В–Њ—А–Њ–≤. –Э–µ–њ–Њ–љ—П—В–љ–Њ, –њ–Њ–≤—В–Њ—А–Є—В—Б—П –ї–Є –љ–∞–є–і–µ–љ–љ—Л–є —Н—Д—Д–µ–Ї—В –њ—А–Є –љ–Њ–≤–Њ–Љ —Н–Ї—Б–њ–µ—А–Є–Љ–µ–љ—В–µ. –Х–і–Є–љ–∞—П –Љ–µ—В–Њ–і–Є–Ї–∞ –Њ—Ж–µ–љ–Ї–Є —Н—Д—Д–µ–Ї—В–Є–≤–љ–Њ—Б—В–Є –Є–љ–≤–µ—Б—В–Є—Ж–Є–Њ–љ–љ—Л—Е –Є–љ–Є—Ж–Є–∞—В–Є–≤ вАФ –Ї–ї—О—З–µ–≤–Њ–є —Б—В—А–Є–Љ –і–ї—П –њ–Њ–і–і–µ—А–ґ–Ї–Є —Ж–Є—Д—А–Њ–≤–Њ–є —В—А–∞–љ—Б—Д–Њ—А–Љ–∞—Ж–Є–Є –Ї–Њ–Љ–њ–∞–љ–Є–є. –Э—Г–ґ–љ–Њ –њ—А–Њ–≤–Њ–і–Є—В—М –Р–С-—В–µ—Б—В–Є—А–Њ–≤–∞–љ–Є–µ. –Х—Б–ї–Є –Њ–љ–Њ –љ–µ —А–∞–±–Њ—В–∞–µ—В, —В–Њ —Б—В–Њ–Є—В –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –≥—А—Г–њ–њ—Г –Љ–µ—В–Њ–і–Њ–≤ –њ—А–Є—З–Є–љ–љ–Њ-—Б–ї–µ–і—Б—В–≤–µ–љ–љ–Њ–≥–Њ –∞–љ–∞–ї–Є–Ј–∞ вАФ Counterfactual Analysis.
–°–∞–Љ–Њ–Њ–±—Б–ї—Г–ґ–Є–≤–∞–љ–Є–µ –і–ї—П –±–Є–Ј–љ–µ—Б-–∞–љ–∞–ї–Є—В–Є–Ї–Њ–≤
–°—А–∞–Ј—Г –і–≤–∞ —Б–њ–Є–Ї–µ—А–∞ –њ—А–µ–і–ї–Њ–ґ–Є–ї–Є –Њ–±—Б—Г–і–Є—В—М —Б–µ–ї—Д-—Б–µ—А–≤–Є—Б—Л –≤ –±–Є–Ј–љ–µ—Б-–∞–љ–∞–ї–Є—В–Є–Ї–µ. –Ш–Љ–µ–љ–љ–Њ –љ–∞ —В–∞–Ї–Њ–є –Є–љ—Б—В—А—Г–Љ–µ–љ—В, –њ–Њ–ї–µ–Ј–љ—Л–є, –≤ –њ–µ—А–≤—Г—О –Њ—З–µ—А–µ–і—М, –±–Є–Ј–љ–µ—Б-–њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—П–Љ, —Б–і–µ–ї–∞–ї–Є —Б—В–∞–≤–Ї—Г –≤ –Ю–±—К–µ–і–Є–љ–µ–љ–љ–Њ–є –Љ–µ—В–∞–ї–ї—Г—А–≥–Є—З–µ—Б–Ї–Њ–є –Ї–Њ–Љ–њ–∞–љ–Є–Є. ¬Ђ–Ь—Л —Е–Њ—В–µ–ї–Є —Б–і–µ–ї–∞—В—М —В–∞–Ї, —З—В–Њ–±—Л –љ–µ –љ—Г–ґ–љ–Њ –±—Л–ї–Њ –њ—А–Є–≤–ї–µ–Ї–∞—В—М –Ш–Ґ-—Б–њ–µ—Ж–Є–∞–ї–Є—Б—В–Њ–≤. –Т–Љ–µ—Б—В–Њ —Н—В–Њ–≥–Њ –Љ—Л —Б–Њ–±—А–∞–ї–Є –Ј–∞–Є–љ—В–µ—А–µ—Б–Њ–≤–∞–љ–љ—Г—О –Ї–Њ–Љ–∞–љ–і—Г –±–Є–Ј–љ–µ—Б-–њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є, –њ—А–Њ–≤–µ–ї–Є –Њ–±—Г—З–µ–љ–Є–µ, —Б–і–µ–ї–∞–ї–Є –Љ–љ–Њ–≥–Њ –Њ–±—Г—З–∞—О—Й–Є—Е –Є–љ—Б—В—А—Г–Ї—Ж–Є–є –Є –≤–Є–і–µ–Њ—А–Њ–ї–Є–Ї–Њ–≤, –Њ—А–≥–∞–љ–Є–Ј–Њ–≤–∞–ї–Є –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М –Ї–Њ–љ—Б—Г–ї—М—В–∞—Ж–Є–є —Б –њ–Њ–і–і–µ—А–ґ–Ї–Њ–є –Є –Ј–∞–Ї—Г–њ–Є–ї–Є –ї–Є—Ж–µ–љ–Ј–Є–Є –љ–∞ –≤—Л–±—А–∞–љ–љ—Л–є —Б–Њ—Д—В вАФ —Н—В–Њ –±—Л–ї–Њ Tableau¬ї, вАФ –Њ–њ–Є—Б—Л–≤–∞–µ—В –Я–∞–≤–µ–ї –£–ї—М–Є—Е–Є–љ, –љ–∞—З–∞–ї—М–љ–Є–Ї –Њ—В–і–µ–ї–∞ –Ї–Њ–Љ–њ–µ—В–µ–љ—Ж–Є–є BI –Є RPA –Ю–±—К–µ–і–Є–љ–µ–љ–љ–Њ–є –Љ–µ—В–∞–ї–ї—Г—А–≥–Є—З–µ—Б–Ї–Њ–є –Ї–Њ–Љ–њ–∞–љ–Є–Є.
–Т 2019 –≥. –њ—А–Њ–µ–Ї—В –њ–Њ –њ–µ—А–µ—Е–Њ–і—Г –љ–∞ BI-—Б–∞–Љ–Њ–Њ–±—Б–ї—Г–ґ–Є–≤–∞–љ–Є–µ –±—Л–ї –Ј–∞–≤–µ—А—И–µ–љ –Є –њ—А–µ–≤–Ј–Њ—И–µ–ї –≤—Б–µ –Њ–ґ–Є–і–∞–љ–Є—П. –Ъ–Њ–Љ–њ–∞–љ–Є—П –±—Л–ї–∞ –≤—Л–љ—Г–ґ–і–µ–љ–∞ –Ј–∞–Ї—Г–њ–Є—В—М –і–Њ–њ–Њ–ї–љ–Є—В–µ–ї—М–љ—Л–µ –ї–Є—Ж–µ–љ–Ј–Є–Є, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –≤—Б–µ –±–Њ–ї—М—И–µ –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є —Б—В—А–µ–Љ–Є–ї–Њ—Б—М —А–∞–±–Њ—В–∞—В—М —В–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ. ¬Ђ–Т—Б–µ –Ј–∞–Ї–Њ–љ—З–Є–ї–Њ—Б—М –љ–∞ –Љ–∞–ґ–Њ—А–љ–Њ–є –љ–Њ—В–µ, –Њ–і–љ–∞–Ї–Њ —Г–ґ–µ —З–µ—А–µ–Ј –Ї–∞–Ї–Њ–µ-—В–Њ –≤—А–µ–Љ—П –Љ—Л —Б—В–Њ–ї–Ї–љ—Г–ї–Є—Б—М —Б –љ–µ–њ—А–µ–і–≤–Є–і–µ–љ–љ—Л–Љ–Є —Б–ї–Њ–ґ–љ–Њ—Б—В—П–Љ–Є¬ї, вАФ –і–µ–ї–Є—В—Б—П —Б–њ–Є–Ї–µ—А. –Я–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–Є –њ–Њ—Б—В–µ–њ–µ–љ–љ–Њ —Б—В–∞–ї–Є —В–µ—А—П—В—М –Є–љ—В–µ—А–µ—Б –Ї BI-—А–∞–Ј—А–∞–±–Њ—В–Ї–µ. –Э–Њ–≤—Л—Е —Б–њ–µ—Ж–Є–∞–ї–Є—Б—В–Њ–≤ –њ—А–Є—Е–Њ–і–Є–ї–Њ—Б—М –њ–Њ—Б—В–Њ—П–љ–љ–Њ –і–Њ–Њ–±—Г—З–∞—В—М. –Я—А–Њ–µ–Ї—В–Њ–Љ –Ј–∞–Є–љ—В–µ—А–µ—Б–Њ–≤–∞–ї–Њ—Б—М —А—Г–Ї–Њ–≤–Њ–і—Б—В–≤–Њ, –Є —В–Њ–њ-–Љ–µ–љ–µ–і–ґ–Љ–µ–љ—В –љ–∞—З–∞–ї –њ—А–Є—Б—Л–ї–∞—В—М –Ј–∞–њ—А–Њ—Б—Л –љ–∞ –і–∞—И–±–Њ—А–і—Л. –£ –±–Є–Ј–љ–µ—Б-–њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є –љ–µ —Е–≤–∞—В–∞–ї–Њ –Ї–≤–∞–ї–Є—Д–Є–Ї–∞—Ж–Є–Є –Є –≤—А–µ–Љ–µ–љ–Є, —З—В–Њ–±—Л –≤—Л–њ–Њ–ї–љ–Є—В—М —А–∞–Ј—А–∞–±–Њ—В–Ї—Г –љ–∞ –і–Њ–ї–ґ–љ–Њ–Љ —Г—А–Њ–≤–љ–µ. –¶–µ–љ—В—А–∞ –Ї–Њ–Љ–њ–µ—В–µ–љ—Ж–Є–є –≤ –Ї–Њ–Љ–њ–∞–љ–Є–Є –љ–µ —Б—Г—Й–µ—Б—В–≤–Њ–≤–∞–ї–Њ, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –љ–µ —Б –њ–Њ–і–і–µ—А–ґ–Ї–Њ–є –њ–Њ–Љ–Њ–≥–∞–ї –њ–Њ–і—А—П–і—З–Є–Ї, –Ї–Њ—В–Њ—А—Л–є –≤–љ–µ–і—А–Є–ї Tableau. –Я–Њ–ї—Г—З–Є–ї–Њ—Б—М, —З—В–Њ —А–µ—Б—Г—А—Б –і–ї—П –Њ–њ–µ—А–∞—В–Є–≤–љ–Њ–≥–Њ —А–µ—И–µ–љ–Є—П –≤–∞–ґ–љ—Л—Е –≤–Њ–њ—А–Њ—Б–Њ–≤, –љ–µ —А–∞–±–Њ—В–∞–µ—В.
–Ъ–Њ–Љ–њ–∞–љ–Є—П –Ј–∞—Б–Њ–Љ–љ–µ–≤–∞–ї–∞—Б—М: –њ—А–∞–≤–Є–ї—М–љ–∞ –ї–Є –±—Л–ї–∞ –µ–µ —Б—В–∞–≤–Ї–∞ –љ–∞ —Б–∞–Љ–Њ–Њ–±—Б–ї—Г–ґ–Є–≤–∞–љ–Є–µ? –Э–µ –ї—Г—З—И–µ –ї–Є –±—Л–ї–Њ –Ј–∞–љ—П—В—М—Б—П —Ж–µ–љ—В—А–∞–ї–Є–Ј–Њ–≤–∞–љ–љ–Њ–є —А–∞–Ј—А–∞–±–Њ—В–Ї–Њ–є, –Ї–∞–Ї —Н—В–Њ –і–µ–ї–∞–µ—В –±–Њ–ї—М—И–Є–љ—Б—В–≤–Њ –Ї–Њ–Љ–њ–∞–љ–Є–є? –Т —А–µ–Ј—Г–ї—М—В–∞—В–µ –і–Є—Б–Ї—Г—Б—Б–Є–є —А–µ—И–Є–ї–Є —А–∞–Ј–≤–Є–≤–∞—В—М –Њ–±–∞ –љ–∞–њ—А–∞–≤–ї–µ–љ–Є—П.
–Ш—В–Њ–≥ —А–∞–±–Њ—В—Л –≤ –і–≤—Г—Е –љ–∞–њ—А–∞–≤–ї–µ–љ–Є—П—Е

–Я—А–∞–Ї—В–Є–Ї–∞ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—П BI-—Б–∞–Љ–Њ–Њ–±—Б–ї—Г–ґ–Є–≤–∞–љ–Є—П –µ—Б—В—М –Є –≤ –Ї–Њ–Љ–њ–∞–љ–Є–Є ¬Ђ–Ъ–Њ–Љ—Г—Б¬ї. –Т–Ј–≥–ї—П–і–Њ–Љ –љ–∞ —Б–µ–ї—Д-—Б–µ—А–≤–Є—Б —Б —В–Њ—З–Ї–Є –Ј—А–µ–љ–Є—П –Ш–Ґ-—Б–њ–µ—Ж–Є–∞–ї–Є—Б—В–Њ–≤ –њ–Њ–і–µ–ї–Є–ї—Б—П –Я–∞–≤–µ–ї –Ь–∞—А—В—Л–љ–Њ–≤, —А—Г–Ї–Њ–≤–Њ–і–Є—В–µ–ї—М BI. ¬Ђ–Ю—Б–љ–Њ–≤–љ–Њ–є –љ–∞—И–µ–є —А–∞–±–Њ—В–Њ–є –±—Л–ї–∞ —А–∞–Ј—А–∞–±–Њ—В–Ї–∞ –њ–Њ –Ј–∞–Ї–∞–Ј–∞–Љ –±–Є–Ј–љ–µ—Б–∞. –С–Є–Ј–љ–µ—Б –њ—А–Є—Е–Њ–і–Є—В –Є —Б–њ—А–∞—И–Є–≤–∞–µ—В: –Љ—Л –њ–Њ—Б—В–∞–≤–Є–ї–Є –≤–Њ—Б–µ–Љ–љ–∞–і—Ж–∞—В—Г—О –Ј–∞–і–∞—З—Г –≤ –њ—А–Є–Њ—А–Є—В–µ—В, –Ї–Њ–≥–і–∞ –≤—Л —Б–і–µ–ї–∞–µ—В–µ? –Ф–∞ –љ–Є–Ї–Њ–≥–і–∞! –Т –Њ–±—Й–µ–Љ, –љ–Њ—А–Љ–∞–ї—М–љ–∞—П –∞–є—В–Є—И–љ–∞—П –ґ–Є–Ј–љ—М¬ї, вАФ —Б–Љ–µ–µ—В—Б—П –і–Њ–Ї–ї–∞–і—З–Є–Ї.
–Я—А–Є —Н—В–Њ–Љ –≤ –Ї–Њ–Љ–њ–∞–љ–Є–Є –Њ–Ї–∞–Ј–∞–ї–Є—Б—М –≥—А–∞–Љ–Њ—В–љ—Л–µ –±–Є–Ј–љ–µ—Б-–њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–Є, –Ї–Њ—В–Њ—А—Л–µ –≥–Њ—В–Њ–≤—Л –±—Л–ї–Є –Ј–∞–љ—П—В—М—Б—П –≤—Б–µ–Љ: –Ј–∞–≥—А—Г–Ј–Ї–Њ–є –і–∞–љ–љ—Л—Е, –Є—Е –љ–Њ—А–Љ–∞–ї–Є–Ј–∞—Ж–Є–µ–є, –≤—Л–≤–Њ–і–Њ–Љ, —Б–Њ–Ј–і–∞–љ–Є–µ–Љ –Љ–Њ–і–µ–ї–µ–є. –Ґ–∞–Ї–Є—Е –ї—О–і–µ–є –±—Л–ї–Њ –љ–µ–Љ–љ–Њ–≥–Њ вАФ –Є–Ј 11 —В—Л—Б —З–µ–ї–Њ–≤–µ–Ї —И—В–∞—В–∞ –њ—А–Є–Љ–µ—А–љ–Њ 10-15. –Ч–∞–і–∞—З–µ–є –Ш–Ґ —Б—В–∞–ї–Њ –Њ–±–µ—Б–њ–µ—З–Є—В—М —В–∞–Ї–Є—Е –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є –њ–ї–∞—В—Д–Њ—А–Љ–Њ–є, –њ–µ—Б–Њ—З–љ–Є—Ж–µ–є, –≥–і–µ –Њ–љ–Є –Љ–Њ–≥–ї–Є –±—Л –і–µ–ї–∞—В—М –љ—Г–ґ–љ—Л–µ –і–ї—П —Б–µ–±—П –≤–µ—Й–Є.
 –Я–∞–≤–µ–ї –£–ї—М–Є—Е–Є–љ, –љ–∞—З–∞–ї—М–љ–Є–Ї –Њ—В–і–µ–ї–∞ –Ї–Њ–Љ–њ–µ—В–µ–љ—Ж–Є–є BI –Є RPA, –Ю–±—К–µ–і–Є–љ–µ–љ–љ–∞—П –Љ–µ—В–∞–ї–ї—Г—А–≥–Є—З–µ—Б–Ї–∞—П –Ї–Њ–Љ–њ–∞–љ–Є—П: –Ь—Л —Б–Њ–±—А–∞–ї–Є –Ј–∞–Є–љ—В–µ—А–µ—Б–Њ–≤–∞–љ–љ—Г—О –Ї–Њ–Љ–∞–љ–і—Г –±–Є–Ј–љ–µ—Б-–њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є, –њ—А–Њ–≤–µ–ї–Є –Њ–±—Г—З–µ–љ–Є–µ, —Б–і–µ–ї–∞–ї–Є –Љ–љ–Њ–≥–Њ –Њ–±—Г—З–∞—О—Й–Є—Е –Є–љ—Б—В—А—Г–Ї—Ж–Є–є –Є –≤–Є–і–µ–Њ—А–Њ–ї–Є–Ї–Њ–≤, –Њ—А–≥–∞–љ–Є–Ј–Њ–≤–∞–ї–Є –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М –Ї–Њ–љ—Б—Г–ї—М—В–∞—Ж–Є–є —Б –њ–Њ–і–і–µ—А–ґ–Ї–Њ–є –Є –Ј–∞–Ї—Г–њ–Є–ї–Є –ї–Є—Ж–µ–љ–Ј–Є–Є –љ–∞ –≤—Л–±—А–∞–љ–љ—Л–є —Б–Њ—Д—В
–Я–∞–≤–µ–ї –£–ї—М–Є—Е–Є–љ, –љ–∞—З–∞–ї—М–љ–Є–Ї –Њ—В–і–µ–ї–∞ –Ї–Њ–Љ–њ–µ—В–µ–љ—Ж–Є–є BI –Є RPA, –Ю–±—К–µ–і–Є–љ–µ–љ–љ–∞—П –Љ–µ—В–∞–ї–ї—Г—А–≥–Є—З–µ—Б–Ї–∞—П –Ї–Њ–Љ–њ–∞–љ–Є—П: –Ь—Л —Б–Њ–±—А–∞–ї–Є –Ј–∞–Є–љ—В–µ—А–µ—Б–Њ–≤–∞–љ–љ—Г—О –Ї–Њ–Љ–∞–љ–і—Г –±–Є–Ј–љ–µ—Б-–њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є, –њ—А–Њ–≤–µ–ї–Є –Њ–±—Г—З–µ–љ–Є–µ, —Б–і–µ–ї–∞–ї–Є –Љ–љ–Њ–≥–Њ –Њ–±—Г—З–∞—О—Й–Є—Е –Є–љ—Б—В—А—Г–Ї—Ж–Є–є –Є –≤–Є–і–µ–Њ—А–Њ–ї–Є–Ї–Њ–≤, –Њ—А–≥–∞–љ–Є–Ј–Њ–≤–∞–ї–Є –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М –Ї–Њ–љ—Б—Г–ї—М—В–∞—Ж–Є–є —Б –њ–Њ–і–і–µ—А–ґ–Ї–Њ–є –Є –Ј–∞–Ї—Г–њ–Є–ї–Є –ї–Є—Ж–µ–љ–Ј–Є–Є –љ–∞ –≤—Л–±—А–∞–љ–љ—Л–є —Б–Њ—Д—В
 –Я–∞–≤–µ–ї –Ь–∞—А—В—Л–љ–Њ–≤, —А—Г–Ї–Њ–≤–Њ–і–Є—В–µ–ї—М BI, ¬Ђ–Ъ–Њ–Љ—Г—Б¬ї: –Т—Б—В—А–∞–Є–≤–∞–љ–Є–µ —З–∞—Б—В–µ–є —Б–µ–ї—Д-—Б–µ—А–≤–Є—Б–∞ –≤ —А–∞–±–Њ—З–Є–µ –њ—А–Њ—Ж–µ—Б—Б—Л –њ–Њ –Њ–±—А–∞–±–Њ—В–Ї–µ –і–∞–љ–љ—Л—Е, –Ї–Њ—В–Њ—А—Л–µ –њ–Њ–і–і–µ—А–ґ–Є–≤–∞–µ—В –Ї–Њ–Љ–∞–љ–і–∞ –Ш–Ґ, вАФ —Н—В–Њ –Њ—Б–љ–Њ–≤–љ–Њ–є –њ—Г—В—М, –Ї–Њ—В–Њ—А—Л–є –Ш–Ґ —Б—В–∞—А–∞–µ—В—Б—П –њ—А–Њ–њ–∞–≥–∞–љ–і–Є—А–Њ–≤–∞—В—М —Б—А–µ–і–Є –±–Є–Ј–љ–µ—Б-–њ–Њ–і—А–∞–Ј–і–µ–ї–µ–љ–Є–є
–Я–∞–≤–µ–ї –Ь–∞—А—В—Л–љ–Њ–≤, —А—Г–Ї–Њ–≤–Њ–і–Є—В–µ–ї—М BI, ¬Ђ–Ъ–Њ–Љ—Г—Б¬ї: –Т—Б—В—А–∞–Є–≤–∞–љ–Є–µ —З–∞—Б—В–µ–є —Б–µ–ї—Д-—Б–µ—А–≤–Є—Б–∞ –≤ —А–∞–±–Њ—З–Є–µ –њ—А–Њ—Ж–µ—Б—Б—Л –њ–Њ –Њ–±—А–∞–±–Њ—В–Ї–µ –і–∞–љ–љ—Л—Е, –Ї–Њ—В–Њ—А—Л–µ –њ–Њ–і–і–µ—А–ґ–Є–≤–∞–µ—В –Ї–Њ–Љ–∞–љ–і–∞ –Ш–Ґ, вАФ —Н—В–Њ –Њ—Б–љ–Њ–≤–љ–Њ–є –њ—Г—В—М, –Ї–Њ—В–Њ—А—Л–є –Ш–Ґ —Б—В–∞—А–∞–µ—В—Б—П –њ—А–Њ–њ–∞–≥–∞–љ–і–Є—А–Њ–≤–∞—В—М —Б—А–µ–і–Є –±–Є–Ј–љ–µ—Б-–њ–Њ–і—А–∞–Ј–і–µ–ї–µ–љ–Є–є
 –Ъ–Њ–љ—Б—В–∞–љ—В–Є–љ –†–∞–Ї–Є—В–Є–љ-–Ъ–µ–є–Ј–µ—А, –і–Є—А–µ–Ї—В–Њ—А –њ–Њ —А–∞–Ј–≤–Є—В–Є—О –±–Є–Ј–љ–µ—Б–∞ Easy Report, Sapiens Solutions: –У–ї–∞–≤–љ–∞—П –њ—А–Њ–±–ї–µ–Љ–∞ –≤–љ–µ–і—А–µ–љ–Є—П –њ–ї–∞—В—Д–Њ—А–Љ –і–∞–љ–љ—Л—Е –Ј–∞–Ї–ї—О—З–∞–µ—В—Б—П –≤ —В–Њ–Љ, —З—В–Њ –њ—А–µ–і–њ—А–Є–љ–Є–Љ–∞—О—В—Б—П —Б–µ—А—М–µ–Ј–љ—Л–µ —Г—Б–Є–ї–Є—П, –і–µ–ї–∞—О—В—Б—П –Ї–Њ–ї–Њ—Б—Б–∞–ї—М–љ—Л–µ –Є–љ–≤–µ—Б—В–Є—Ж–Є–Є, –∞ –≤ —А–µ–Ј—Г–ї—М—В–∞—В–µ –≤—Л—Е–Њ–і–Є—В, —З—В–Њ –њ–Њ–ї—М–Ј—Г—О—В—Б—П –і–∞–љ–љ—Л–Љ–Є –Є –Њ—В—З–µ—В–∞–Љ–Є –ї–Є—И—М 10% —Б–Њ—В—А—Г–і–љ–Є–Ї–Њ–≤ –Ї–Њ–Љ–њ–∞–љ–Є–Є
–Ъ–Њ–љ—Б—В–∞–љ—В–Є–љ –†–∞–Ї–Є—В–Є–љ-–Ъ–µ–є–Ј–µ—А, –і–Є—А–µ–Ї—В–Њ—А –њ–Њ —А–∞–Ј–≤–Є—В–Є—О –±–Є–Ј–љ–µ—Б–∞ Easy Report, Sapiens Solutions: –У–ї–∞–≤–љ–∞—П –њ—А–Њ–±–ї–µ–Љ–∞ –≤–љ–µ–і—А–µ–љ–Є—П –њ–ї–∞—В—Д–Њ—А–Љ –і–∞–љ–љ—Л—Е –Ј–∞–Ї–ї—О—З–∞–µ—В—Б—П –≤ —В–Њ–Љ, —З—В–Њ –њ—А–µ–і–њ—А–Є–љ–Є–Љ–∞—О—В—Б—П —Б–µ—А—М–µ–Ј–љ—Л–µ —Г—Б–Є–ї–Є—П, –і–µ–ї–∞—О—В—Б—П –Ї–Њ–ї–Њ—Б—Б–∞–ї—М–љ—Л–µ –Є–љ–≤–µ—Б—В–Є—Ж–Є–Є, –∞ –≤ —А–µ–Ј—Г–ї—М—В–∞—В–µ –≤—Л—Е–Њ–і–Є—В, —З—В–Њ –њ–Њ–ї—М–Ј—Г—О—В—Б—П –і–∞–љ–љ—Л–Љ–Є –Є –Њ—В—З–µ—В–∞–Љ–Є –ї–Є—И—М 10% —Б–Њ—В—А—Г–і–љ–Є–Ї–Њ–≤ –Ї–Њ–Љ–њ–∞–љ–Є–Є
 –Ш–≥–Њ—А—М –Я–∞–љ—В–µ–ї–µ–µ–≤, –∞—А—Е–Є—В–µ–Ї—В–Њ—А –Є —Б–Њ—Г—З—А–µ–і–Є—В–µ–ї—М –Ї–Њ–Љ–њ–∞–љ–Є–Є Sapiens Solutions: –Т—Б–µ, —З—В–Њ –љ—Г–ґ–љ–Њ –љ–∞—И–µ–Љ—Г –Ї–ї–Є–µ–љ—В—Г, —З—В–Њ–±—Л –љ–∞—З–∞—В—М –њ–Њ–ї—Г—З–Є—В—М –і–∞–љ–љ—Л–µ, вАФ —Н—В–Њ –њ–Њ–і–≥–Њ—В–Њ–≤–Є—В—М –≤–Є—В—А–Є–љ—Г –Є –њ–Њ–≤–µ—А—Е –љ–µ–µ –Њ–њ–Є—Б–∞—В—М –њ–Њ–љ—П—В–Є–є–љ–Њ-—Б–µ–Љ–∞–љ—В–Є—З–µ—Б–Ї–Є–є —Б–ї–Њ–є
–Ш–≥–Њ—А—М –Я–∞–љ—В–µ–ї–µ–µ–≤, –∞—А—Е–Є—В–µ–Ї—В–Њ—А –Є —Б–Њ—Г—З—А–µ–і–Є—В–µ–ї—М –Ї–Њ–Љ–њ–∞–љ–Є–Є Sapiens Solutions: –Т—Б–µ, —З—В–Њ –љ—Г–ґ–љ–Њ –љ–∞—И–µ–Љ—Г –Ї–ї–Є–µ–љ—В—Г, —З—В–Њ–±—Л –љ–∞—З–∞—В—М –њ–Њ–ї—Г—З–Є—В—М –і–∞–љ–љ—Л–µ, вАФ —Н—В–Њ –њ–Њ–і–≥–Њ—В–Њ–≤–Є—В—М –≤–Є—В—А–Є–љ—Г –Є –њ–Њ–≤–µ—А—Е –љ–µ–µ –Њ–њ–Є—Б–∞—В—М –њ–Њ–љ—П—В–Є–є–љ–Њ-—Б–µ–Љ–∞–љ—В–Є—З–µ—Б–Ї–Є–є —Б–ї–Њ–є
 –Ѓ—А–Є–є –°–Є—А–Њ—В–∞, —Н–Ї—Б–њ–µ—А—В –≤ –Њ–±–ї–∞—Б—В–Є –±–Њ–ї—М—И–Є—Е –і–∞–љ–љ—Л—Е –Є –Є—Б–Ї—Г—Б—Б—В–≤–µ–љ–љ–Њ–≥–Њ –Є–љ—В–µ–ї–ї–µ–Ї—В–∞: –Ъ–Њ–≥–і–∞ —Б—З–Є—В–∞–µ—В—Б—П, —З—В–Њ –≤—Б–µ –Љ–Њ–ґ–љ–Њ –Њ—Ж–Є—Д—А–Њ–≤–∞—В—М вАФ —Н—В–Њ –Љ–∞—В–µ–Љ–∞—В–Є—З–µ—Б–Ї–Є–є —Н–Ї—Б—В—А–µ–Љ–Є–Ј–Љ, —Д–∞–љ–∞—В–Є–Ј–Љ –Є –љ–µ–≤–µ–ґ–µ—Б—В–≤–Њ
–Ѓ—А–Є–є –°–Є—А–Њ—В–∞, —Н–Ї—Б–њ–µ—А—В –≤ –Њ–±–ї–∞—Б—В–Є –±–Њ–ї—М—И–Є—Е –і–∞–љ–љ—Л—Е –Є –Є—Б–Ї—Г—Б—Б—В–≤–µ–љ–љ–Њ–≥–Њ –Є–љ—В–µ–ї–ї–µ–Ї—В–∞: –Ъ–Њ–≥–і–∞ —Б—З–Є—В–∞–µ—В—Б—П, —З—В–Њ –≤—Б–µ –Љ–Њ–ґ–љ–Њ –Њ—Ж–Є—Д—А–Њ–≤–∞—В—М вАФ —Н—В–Њ –Љ–∞—В–µ–Љ–∞—В–Є—З–µ—Б–Ї–Є–є —Н–Ї—Б—В—А–µ–Љ–Є–Ј–Љ, —Д–∞–љ–∞—В–Є–Ј–Љ –Є –љ–µ–≤–µ–ґ–µ—Б—В–≤–Њ
–Р–љ–∞–ї–Є—В–Є–Ї–∞ –≤ ¬Ђ–Ъ–Њ–Љ—Г—Б–µ¬ї –±—Л–ї–∞ —А–∞–Ј–і–µ–ї–µ–љ–∞ –љ–∞ 2 –±–Њ–ї—М—И–Є—Е —Б–µ–≥–Љ–µ–љ—В–∞: –Њ—В—З–µ—В–љ–Њ—Б—В—М –Є –њ—А–Њ–і–≤–Є–љ—Г—В–∞—П –∞–љ–∞–ї–Є—В–Є–Ї–∞. –Т –њ–µ—А–≤–Њ–Љ —Б–µ–≥–Љ–µ–љ—В–µ —А–∞–±–Њ—В–∞—О—В —А–µ—И–µ–љ–Є—П, –њ–Њ–ї–љ–Њ—Б—В—М—О –њ–Њ–і–і–µ—А–ґ–Є–≤–∞–µ–Љ—Л–µ –Ш–Ґ-–і–µ–њ–∞—А—В–∞–Љ–µ–љ—В–Њ–Љ. –Ч–і–µ—Б—М –±–Њ–ї—М—И–Њ–µ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є. –Т–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В–Є –Є–Ј–Љ–µ–љ–µ–љ–Є—П –∞–ї–≥–Њ—А–Є—В–Љ–Њ–≤ —Б –Є—Е —Б—В–Њ—А–Њ–љ—Л –Љ–Є–љ–Є–Љ–∞–ї—М–љ—Л, —Е–Њ—В—П –Њ–љ–Є –Љ–Њ–≥—Г—В –Љ–µ–љ—П—В—М –≤–Є–Ј—Г–∞–ї–Є–Ј–∞—Ж–Є—О –Њ—В—З–µ—В–Њ–≤, –љ–Њ –≤ –Њ–≥—А–∞–љ–Є—З–µ–љ–љ–Њ–Љ –Љ–∞—Б—И—В–∞–±–µ. –Р–ї–≥–Њ—А–Є—В–Љ—Л –њ—А–µ–Њ–±—А–∞–Ј–Њ–≤–∞–љ–Є—П –і–∞–љ–љ—Л—Е —Ж–µ–љ—В—А–∞–ї–Є–Ј–Њ–≤–∞–љ—Л, —Б–Њ–Ј–і–∞–љ—Л —Б–њ–µ—Ж–Є–∞–ї—М–љ—Л–µ —А–µ–≥–ї–∞–Љ–µ–љ—В—Л –њ–Њ –Є—Е –Є–Ј–Љ–µ–љ–µ–љ–Є—О.
–І—В–Њ –Ї–∞—Б–∞–µ—В—Б—П –≤—В–Њ—А–Њ–≥–Њ —Б–µ–≥–Љ–µ–љ—В–∞, —В–Њ –Є–Љ–µ–љ–љ–Њ —В—Г—В –Є –±—Л–ї–Њ —А–µ–∞–ї–Є–Ј–Њ–≤–∞–љ–Њ —Б–∞–Љ–Њ–Њ–±—Б–ї—Г–ґ–Є–≤–∞–љ–Є–µ вАФ –Ї–Њ–Љ–∞–љ–і–∞ –Ш–Ґ –њ–Њ–і–і–µ—А–ґ–Є–≤–∞–µ—В —В–Њ–ї—М–Ї–Њ –Є–љ—Д—А–∞—Б—В—А—Г–Ї—В—Г—А—Г. –І–Є—Б–ї–Њ –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є –Њ–≥—А–∞–љ–Є—З–µ–љ–Њ, –љ–Њ –Ј–∞—В–Њ –∞–ї–≥–Њ—А–Є—В–Љ—Л –њ—А–µ–Њ–±—А–∞–Ј–Њ–≤–∞–љ–Є—П –і–∞–љ–љ—Л—Е –Љ–Њ–≥—Г—В —Б–Њ–Ј–і–∞–≤–∞—В—М—Б—П –Є –Є–Ј–Љ–µ–љ—П—В—М—Б—П –∞–љ–∞–ї–Є—В–Є–Ї–∞–Љ–Є –±–Є–Ј–љ–µ—Б-–њ–Њ–і—А–∞–Ј–і–µ–ї–µ–љ–Є–є. –Ф–∞–ї–µ–µ —Б–Њ–Ј–і–∞–µ—В—Б—П –њ—А–Њ—Ж–µ—Б—Б –њ–µ—А–µ–і–∞—З–Є –∞–љ–∞–ї–Є—В–Є—З–µ—Б–Ї–Є—Е —А–µ—И–µ–љ–Є–є –љ–∞ —Б—В–Њ—А–Њ–љ—Г –Ш–Ґ, –њ–Њ—Б–ї–µ —З–µ–≥–Њ –њ—А–Њ–і—Г–Ї—В–Є–≤–љ–Њ–µ —А–µ—И–µ–љ–Є–µ –љ–∞—З–Є–љ–∞–µ—В –њ–Њ–і–і–µ—А–ґ–Є–≤–∞—В—М —Г–ґ–µ —Н—В–Њ—В –і–µ–њ–∞—А—В–∞–Љ–µ–љ—В.
–Т —А–∞–Љ–Ї–∞—Е –њ—А–Њ–µ–Ї—В–∞ –±—Л–ї–Њ –Њ—В—Б–Љ–Њ—В—А–µ–љ–Њ –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –њ–µ—А—Б–њ–µ–Ї—В–Є–≤–љ—Л—Е —А–µ—И–µ–љ–Є–є, –њ—А–Њ–≤–µ–і–µ–љ—Л –њ–Є–ї–Њ—В—Л. –Т –Є—В–Њ–≥–µ –±—Л–ї–Є –≤—Л–±—А–∞–љ—Л Knime analytic server вАФ —Б–Є—Б—В–µ–Љ–∞ self-service ETL –Є –≤–Є–Ј—Г–∞–ї—М–љ–Њ–≥–Њ –∞–љ–∞–ї–Є–Ј–∞ –і–∞–љ–љ—Л—Е; Tableau вАФ –≤–Є–Ј—Г–∞–ї–Є–Ј–∞—Ж–Є—П –і–∞–љ–љ—Л—Е; Superset вАФ —Б–Є—Б—В–µ–Љ–∞ –≤–Є–Ј—Г–∞–ї–Є–Ј–∞—Ж–Є—П –і–∞–љ–љ—Л—Е; Arenadata DB вАФ —А–µ—И–µ–љ–Є–µ –і–ї—П –µ–і–Є–љ–Њ–≥–Њ –∞–љ–∞–ї–Є—В–Є—З–µ—Б–Ї–Њ–≥–Њ —Е—А–∞–љ–Є–ї–Є—Й–∞; JupyterHUB вАФ —Б–Є—Б—В–µ–Љ–∞ –њ—А–Њ–і–≤–Є–љ—Г—В–Њ–є –∞–љ–∞–ї–Є—В–Є–Ї–Є; –Ї–ї–∞—Б—В–µ—А –≤–Є—А—В—Г–∞–ї—М–љ—Л—Е –Љ–∞—И–Є–љ —Б —Г–≤–µ–ї–Є—З–µ–љ–љ—Л–Љ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ–Љ —А–µ—Б—Г—А—Б–Њ–≤ (5 –≤–Є—А—В—Г–∞–ї—М–љ—Л—Е –Љ–∞—И–Є–љ —Б 4 —П–і—А–∞–Љ–Є –Є 100 –У–± –Ю–Я, —Б –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М—О –Њ–і–љ–Њ–≤—А–µ–Љ–µ–љ–љ–Њ–≥–Њ –≤—Е–Њ–і–∞ –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є).
–Т –Ї–Њ–Љ–њ–∞–љ–Є–Є —В–∞–Ї–ґ–µ –±—Л–ї —Б–Њ–Ј–і–∞–љ –њ–Њ—А—В–∞–ї –њ—А–Њ–і–≤–Є–љ—Г—В–Њ–є –∞–љ–∞–ї–Є—В–Є–Ї–Є –љ–∞ –Њ—Б–љ–Њ–≤–µ —А–µ—И–µ–љ–Є—П JupyterHUB. –Ю–љ –і–∞–µ—В –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М –Ј–∞–њ—Г—Б–Ї–∞—В—М —Б–Ї—А–Є–њ—В—Л –љ–∞ Python –љ–∞ —Б–µ—А–≤–µ—А–µ —Б –і–Њ—Б—В—Г–њ–љ—Л–Љ–Є —А–µ—Б—Г—А—Б–∞–Љ–Є, –µ—Б–ї–Є –љ–∞–і–Њ, —В–Њ –њ–Њ —А–∞—Б–њ–Є—Б–∞–љ–Є—О. –°–Ї—А–Є–њ—В—Л –Љ–Њ–ґ–љ–Њ –њ–µ—А–µ–і–∞–≤–∞—В—М –Љ–µ–ґ–і—Г –∞–љ–∞–ї–Є—В–Є–Ї–∞–Љ–Є.
–Т—Б—В—А–∞–Є–≤–∞–љ–Є–µ —З–∞—Б—В–µ–є —Б–µ–ї—Д-—Б–µ—А–≤–Є—Б–∞ –≤ —А–∞–±–Њ—З–Є–µ –њ—А–Њ—Ж–µ—Б—Б—Л –њ–Њ –Њ–±—А–∞–±–Њ—В–Ї–µ –і–∞–љ–љ—Л—Е, –Ї–Њ—В–Њ—А—Л–µ –њ–Њ–і–і–µ—А–ґ–Є–≤–∞–µ—В –Ї–Њ–Љ–∞–љ–і–∞ –Ш–Ґ, вАФ —Н—В–Њ –Њ—Б–љ–Њ–≤–љ–Њ–є –њ—Г—В—М, –Ї–Њ—В–Њ—А—Л–є –Ш–Ґ —Б—В–∞—А–∞–µ—В—Б—П –њ—А–Њ–њ–∞–≥–∞–љ–і–Є—А–Њ–≤–∞—В—М —Б—А–µ–і–Є –±–Є–Ј–љ–µ—Б-–њ–Њ–і—А–∞–Ј–і–µ–ї–µ–љ–Є–є. –Ю—Б–љ–Њ–≤–љ—Г—О —А–∞–±–Њ—В—Г –њ–Њ –њ–Њ–і–≥–Њ—В–Њ–≤–Ї–µ –Є —Е—А–∞–љ–µ–љ–Є—О –і–∞–љ–љ—Л—Е –љ–∞ —Б–µ–±—П –±–µ—А–µ—В –Ш–Ґ, —В–Њ–≥–і–∞ –Ї–∞–Ї –Њ—Б—В–∞–ї—М–љ—Л–µ –Њ—В–і–µ–ї—Л —А–µ–∞–ї–Є–Ј—Г—О—В —В–Њ–ї—М–Ї–Њ —З–∞—Б—В—М –∞–ї–≥–Њ—А–Є—В–Љ–Њ–≤ –њ–Њ –Њ–±—А–∞–±–Њ—В–Ї–µ –і–∞–љ–љ—Л—Е. –Ґ–∞–Ї–Є–µ –∞–ї–≥–Њ—А–Є—В–Љ—Л –Ш–Ґ-–і–µ–њ–∞—А—В–∞–Љ–µ–љ—В –≤—Б—В—А–∞–Є–≤–∞–µ—В –≤ —Б—В–∞–љ–і–∞—А—В–љ—Л–µ —Ж–µ–њ–Њ—З–Ї–Є –Њ–±—А–∞–±–Њ—В–Ї–Є –і–∞–љ–љ—Л—Е –≤ —Е—А–∞–љ–Є–ї–Є—Й–µ, –∞ –љ–∞ –±–Є–Ј–љ–µ—Б-—Б–Њ—В—А—Г–і–љ–Є–Ї–∞—Е –Њ—Б—В–∞–µ—В—Б—П –≤–Є–Ј—Г–∞–ї–Є–Ј–∞—Ж–Є—П.
–Э–µ —Б—В–µ—Б–љ—П—В—М—Б—П –Є –њ–Њ–і–Ї–ї—О—З–Є—В—М –Ї BI-–∞–љ–∞–ї–Є—В–Є–Ї–µ —Б—А–∞–Ј—Г —В—Л—Б—П—З—Г –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є –њ—А–µ–і–ї–Њ–ґ–Є–ї –Ъ–Њ–љ—Б—В–∞–љ—В–Є–љ –†–∞–Ї–Є—В–Є–љ-–Ъ–µ–є–Ј–µ—А, –і–Є—А–µ–Ї—В–Њ—А –њ–Њ —А–∞–Ј–≤–Є—В–Є—О –±–Є–Ј–љ–µ—Б–∞ Easy Report. –У–ї–∞–≤–љ–∞—П –њ—А–Њ–±–ї–µ–Љ–∞ –≤–љ–µ–і—А–µ–љ–Є—П –њ–ї–∞—В—Д–Њ—А–Љ –і–∞–љ–љ—Л—Е –Ј–∞–Ї–ї—О—З–∞–µ—В—Б—П –≤ —В–Њ–Љ, —З—В–Њ –њ—А–µ–і–њ—А–Є–љ–Є–Љ–∞—О—В—Б—П —Б–µ—А—М–µ–Ј–љ—Л–µ —Г—Б–Є–ї–Є—П, –і–µ–ї–∞—О—В—Б—П –Ї–Њ–ї–Њ—Б—Б–∞–ї—М–љ—Л–µ –Є–љ–≤–µ—Б—В–Є—Ж–Є–Є, –∞ –≤ —А–µ–Ј—Г–ї—М—В–∞—В–µ –≤—Л—Е–Њ–і–Є—В, —З—В–Њ –њ–Њ–ї—М–Ј—Г—О—В—Б—П –і–∞–љ–љ—Л–Љ–Є –Є –Њ—В—З–µ—В–∞–Љ–Є –ї–Є—И—М 10% —Б–Њ—В—А—Г–і–љ–Є–Ї–Њ–≤ –Ї–Њ–Љ–њ–∞–љ–Є–Є. –Ф–∞–љ–љ—Л–µ –і–Њ–ї–ґ–љ—Л –±—Л—В—М –±–Њ–ї–µ–µ –і–Њ—Б—В—Г–њ–љ—Л.
–Ю—В–≤–µ—В–Њ–Љ –љ–∞ —Н—В—Г –Ј–∞–і–∞—З—Г —Б—В–∞–ї –Є–љ—Б—В—А—Г–Љ–µ–љ—В Easy Report, –Ї–Њ—В–Њ—А—Л–є –і–∞–µ—В –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М –њ–Њ–ї—Г—З–∞—В—М –Њ—В—З–µ—В–љ–Њ—Б—В—М —З–µ—А–µ–Ј –ї—О–±–Њ–є –≤—Л–±—А–∞–љ–љ—Л–є –Љ–µ—Б—Б–µ–љ–і–ґ–µ—А. –Ю–љ –њ—А–Њ—Б—В –≤ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–Є, –њ–Њ–Ј–≤–Њ–ї—П–µ—В –і–µ–ї–∞—В—М –Ј–∞–њ—А–Њ—Б—Л –љ–∞ –µ—Б—В–µ—Б—В–≤–µ–љ–љ–Њ–Љ —П–Ј—Л–Ї–µ, —А–∞–±–Њ—В–∞–µ—В —Б –і–∞–љ–љ—Л–Љ–Є –ї—О–±–Њ–≥–Њ —В–Є–њ–∞ –Є –≤—Б–µ–≥–і–∞ –њ–Њ–і —А—Г–Ї–Њ–є вАФ —Б–Љ–∞—А—В—Д–Њ–љ—Л —Б–µ–є—З–∞—Б –µ—Б—В—М –њ—А–∞–Ї—В–Є—З–µ—Б–Ї–Є —Г –≤—Б–µ—Е. –Ф–∞–љ–љ—Л–µ –≤—Л–≤–Њ–і—П—В—Б—П –≤ –њ—А–Њ—Б—В–Њ–Љ —Д–Њ—А–Љ–∞—В–µ –Є –љ–µ —В—А–µ–±—Г—О—В –њ—А–µ–і–≤–∞—А–Є—В–µ–ї—М–љ–Њ–є –њ–Њ–і–≥–Њ—В–Њ–≤–Ї–Є.
¬ЂEasy Report –Њ—З–µ–љ—М —Г–і–Њ–±–µ–љ –і–ї—П —В–Њ–њ-–Љ–µ–љ–µ–і–ґ–Љ–µ–љ—В–∞, —В–Њ—А–≥–Њ–≤—Л—Е –њ—А–µ–і—Б—В–∞–≤–Є—В–µ–ї–µ–є –Є –і–ї—П –≤—Б–µ—Е, –Ї—В–Њ –љ–µ –Є–Љ–µ–µ—В –Љ–Њ—Й–љ–Њ–≥–Њ –±–µ–Ї–≥—А–∞—Г–љ–і–∞ –≤ —Б—Д–µ—А–µ –∞–љ–∞–ї–Є—В–Є–Ї–Є, –љ–Њ –љ—Г–ґ–і–∞–µ—В—Б—П –≤ –Ї–Њ–љ–Ї—А–µ—В–љ—Л—Е –Њ—В–≤–µ—В–∞—Е –њ—А—П–Љ–Њ —Б–µ–є—З–∞—Б. –Э–∞–њ—А–Є–Љ–µ—А, —В–Њ—А–≥–Њ–≤—Л–є –њ—А–µ–і—Б—В–∞–≤–Є—В–µ–ї—М —Г–µ—Е–∞–ї –≤ –Ґ–∞–Љ–±–Њ–≤—Б–Ї—Г—О –Њ–±–ї–∞—Б—В—М –Є –µ–≥–Њ —Б–њ—А–∞—И–Є–≤–∞—О—В, –Ї–∞–Ї–Є–µ –њ—А–Њ–і—Г–Ї—В—Л –Ї–Њ–Љ–њ–∞–љ–Є–Є –±—Л–ї–Є —Г –≤–∞—Б —В–Њ–њ-5 –≤ –њ–µ—А–≤–Њ–Љ –Ї–≤–∞—А—В–∞–ї–µ 2021 –≥–Њ–і–∞. –І–µ–ї–Њ–≤–µ–Ї –Љ–Њ–ґ–µ—В –Њ—В–Ї—А—Л—В—М —Б–≤–Њ–є ¬Ђ–Ґ–µ–ї–µ–≥—А–∞–Љ¬ї, –љ–∞–њ–Є—Б–∞—В—М ¬Ђ—В–Њ–њ-5¬ї –Є ¬Ђ2021¬ї –Є –Љ–Њ–Љ–µ–љ—В–∞–ї—М–љ–Њ –њ–Њ–ї—Г—З–Є—В—М –Њ—В–≤–µ—В¬ї, вАФ –≥–Њ–≤–Њ—А–Є—В –Ъ–Њ–љ—Б—В–∞–љ—В–Є–љ –†–∞–Ї–Є—В–Є–љ-–Ъ–µ–є–Ј–µ—А.
–Р—А—Е–Є—В–µ–Ї—В—Г—А–∞ Easy Report
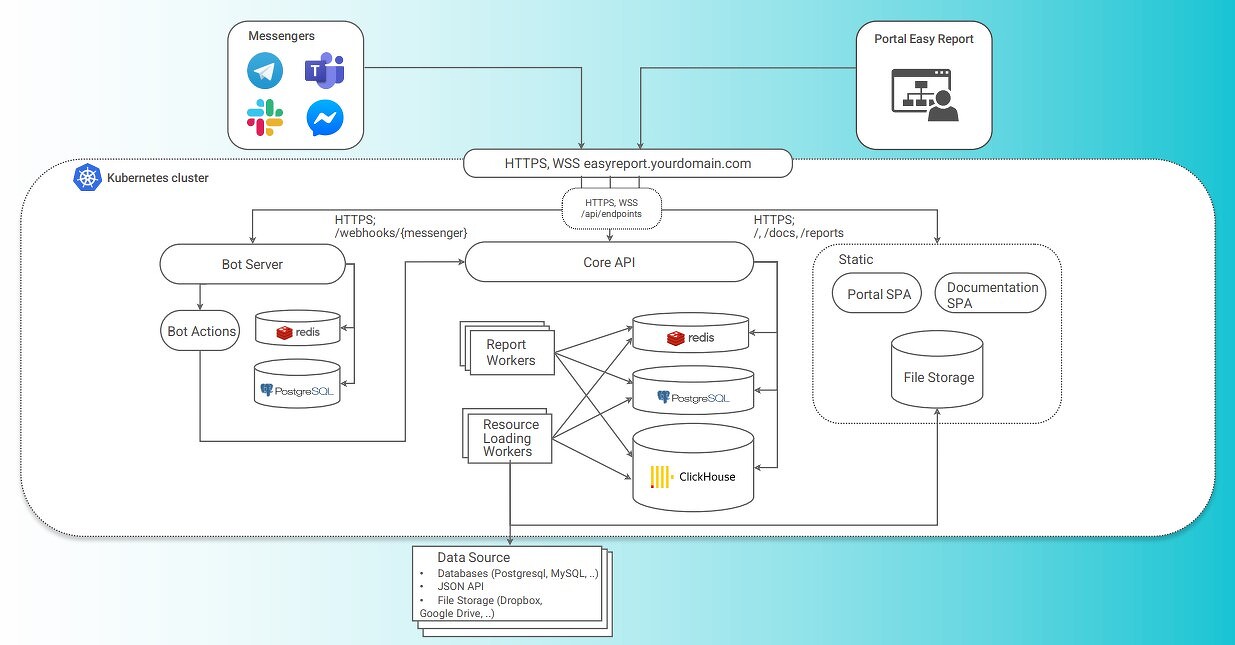
–†–∞–Ј–≤–µ—А—В—Л–≤–∞–љ–Є–µ Easy Report –Ј–∞–љ–Є–Љ–∞–µ—В –≤—Б–µ–≥–Њ 4 –љ–µ–і–µ–ї–Є –Є –і–Њ—Б—В—Г–њ–љ–Њ –Ї–∞–Ї –≤–љ—Г—В—А–Є –Ї–Њ–љ—В—Г—А–∞ –њ—А–µ–і–њ—А–Є—П—В–Є—П, —В–∞–Ї –Є –≤ –Њ–±–ї–∞–Ї–µ. ¬Ђ–Т—Б–µ, —З—В–Њ –љ—Г–ґ–љ–Њ –љ–∞—И–µ–Љ—Г –Ї–ї–Є–µ–љ—В—Г, —З—В–Њ–±—Л –љ–∞—З–∞—В—М –њ–Њ–ї—Г—З–Є—В—М –і–∞–љ–љ—Л–µ, вАФ —Н—В–Њ –њ–Њ–і–≥–Њ—В–Њ–≤–Є—В—М –≤–Є—В—А–Є–љ—Г –Є –њ–Њ–≤–µ—А—Е –љ–µ–µ –Њ–њ–Є—Б–∞—В—М –њ–Њ–љ—П—В–Є–є–љ–Њ-—Б–µ–Љ–∞–љ—В–Є—З–µ—Б–Ї–Є–є —Б–ї–Њ–є, –≤ –Ї–Њ—В–Њ—А–Њ–Љ —В–µ—А–Љ–Є–љ—Л, –Є—Б–њ–Њ–ї—М–Ј—Г–µ–Љ—Л–µ –≤ –Ї–Њ–Љ–њ–∞–љ–Є–Є, –±—Г–і—Г—В –њ—А–Є–≤—П–Ј–∞–љ—Л –Ї –Ї–Њ–љ–Ї—А–µ—В–љ—Л–Љ —Н–ї–µ–Љ–µ–љ—В–∞–Љ –і–∞–љ–љ—Л—Е. –С–Њ–ї—М—И–µ –љ–µ –љ—Г–ґ–љ–Њ —Б—В—А–Њ–Є—В—М –Љ–љ–Њ–ґ–µ—Б—В–≤–Њ –і–∞—И–±–Њ—А–і–Њ–≤ –і–ї—П –Ї–∞–ґ–і–Њ–≥–Њ –Є–Ј –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–µ–є¬ї, вАФ –≥–Њ–≤–Њ—А–Є—В –Ш–≥–Њ—А—М –Я–∞–љ—В–µ–ї–µ–µ–≤, –∞—А—Е–Є—В–µ–Ї—В–Њ—А –Є —Б–Њ—Г—З—А–µ–і–Є—В–µ–ї—М –Ї–Њ–Љ–њ–∞–љ–Є–Є Easy Report.
–Э–µ–Љ–љ–Њ–≥–Њ —Д–Є–ї–Њ—Б–Њ—Д–Є–Є
–Я—А–µ–і–ї–Њ–ґ–Є–ї –Ј–∞–≤–µ—А—И–Є—В—М —Б–µ–Ї—Ж–Є—О —Д–Є–ї–Њ—Б–Њ—Д—Б–Ї–Њ–є –±–µ—Б–µ–і–Њ–є –Њ —В–µ–Њ—А–Є–Є –Є –Ј–љ–∞–љ–Є–Є –Ї–∞–Ї —В–∞–Ї–Њ–≤–Њ–Љ –Ѓ—А–Є–є –°–Є—А–Њ—В–∞, —Н–Ї—Б–њ–µ—А—В –≤ –Њ–±–ї–∞—Б—В–Є –±–Њ–ї—М—И–Є—Е –і–∞–љ–љ—Л—Е –Є –Є—Б–Ї—Г—Б—Б—В–≤–µ–љ–љ–Њ–≥–Њ –Є–љ—В–µ–ї–ї–µ–Ї—В–∞. –Я–Њ –µ–≥–Њ –Љ–љ–µ–љ–Є—О, –љ–µ–Ј–љ–∞–љ–Є–µ —В–µ–Њ—А–Є–Є –њ—А–Є–≤–Њ–і–Є—В –Ї —В–Њ–Љ—Г, —З—В–Њ –Ї–∞–ґ–і–∞—П –Ј–∞–і–∞—З–∞ –≤–Њ—Б–њ—А–Є–љ–Є–Љ–∞–µ—В—Б—П –Ї–∞–Ї –љ–Њ–≤–∞—П. –Э–Њ –Ј–∞–і–∞—З–Є –Љ–Њ–≥—Г—В –±—Л—В—М –Њ–±—К–µ–і–Є–љ–µ–љ—Л –Њ–±—Й–µ–є –Љ–µ—В–Њ–і–Њ–ї–Њ–≥–Є–µ–є –Є –Є–Љ–µ—В—М –Њ–±—Й–Є–µ –њ—А–Є–љ—Ж–Є–њ—Л —А–µ—И–µ–љ–Є—П. ¬Ђ–Т —Г—Б–ї–Њ–≤–Є—П—Е –∞–≥—А–µ—Б—Б–Є–≤–љ–Њ–є –≤–љ–µ—И–љ–µ–є —Б—А–µ–і—Л, —Б–∞–љ–Ї—Ж–Є–є —В—П–ґ–µ–ї–Њ —А–∞–±–Њ—В–∞—В—М —Н–Ї—Б—В–µ–љ—Б–Є–≤–љ–Њ. –Э—Г–ґ–љ–Њ —А–∞–±–Њ—В–∞—В—М –Є–љ—В–µ–љ—Б–Є–≤–љ–Њ –Є –≤—Л–ґ–Є–Љ–∞—В—М –Љ–∞–Ї—Б–Є–Љ—Г–Љ –Є–Ј —В–Њ–≥–Њ, —З—В–Њ –µ—Б—В—М¬ї, вАФ –≥–Њ–≤–Њ—А–Є—В –Ѓ—А–Є–є –°–Є—А–Њ—В–∞.
–І—В–Њ–±—Л –љ–µ ¬Ђ–Ї–∞—В–∞—В—М –Ї–≤–∞–і—А–∞—В–љ–Њ–µ, –љ–Њ—Б–Є—В—М –Ї—А—Г–≥–ї–Њ–µ¬ї, –Љ–Њ–ґ–љ–Њ –≤–Њ—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М—Б—П –Ј–љ–∞–љ–Є—П–Љ–Є, –њ–Њ–Ј–≤–Њ–ї—П—О—Й–Є–Љ–Є –њ—А–µ–≤—А–∞—В–Є—В—М –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—О –≤ –ї—Г—З—И–µ–µ –њ—А–∞–Ї—В–Є—З–µ—Б–Ї–Њ–µ –і–µ–є—Б—В–≤–Є–µ –ї—О–±–Њ–≥–Њ –Љ–∞—Б—И—В–∞–±–∞. Decision intelligence –њ—А–µ–і–љ–∞–Ј–љ–∞—З–µ–љ–∞ –і–ї—П —Б–Њ–Ј–і–∞–љ–Є—П –њ—А–Њ–≥—А–∞–Љ–Љ–љ—Л—Е —Б–Є—Б—В–µ–Љ, –Ї–Њ—В–Њ—А—Л–µ –њ–Њ–Љ–Њ–≥—Г—В —Б–і–µ–ї–∞—В—М –ї—Г—З—И–Є–є –≤—Л–±–Њ—А —А–µ—И–µ–љ–Є—П (data science) —Б—А–µ–і–Є –≤–Њ–Ј–Љ–Њ–ґ–љ—Л—Е –∞–ї—М—В–µ—А–љ–∞—В–Є–≤, —А–µ–Ї–Њ–Љ–µ–љ–і–Њ–≤–∞—В—М –і–∞–ї—М–љ–µ–є—И–Є–µ –і–µ–є—Б—В–≤–Є—П –Є –њ—А–µ–і–ї–Њ–ґ–Є—В—М —А–µ–Ј—Г–ї—М—В–∞—В—Л –Ј–∞–Є–љ—В–µ—А–µ—Б–Њ–≤–∞–љ–љ—Л–Љ –ї–Є—Ж–∞–Љ.
–Т –Њ—Б–љ–Њ–≤–µ Decision intelligence –ї–µ–ґ–∞—В –Љ–∞—В–µ–Љ–∞—В–Є—З–µ—Б–Ї–Є–µ –Љ–µ—В–Њ–і—Л, —А–∞–Ј—А–∞–±–∞—В—Л–≤–∞–µ–Љ—Л–µ –≤ —А–∞–Љ–Ї–∞—Е –і–Є—Б—Ж–Є–њ–ї–Є–љ, —В–∞–Ї–Є—Е –Ї–∞–Ї —В–µ–Њ—А–Є–Є –Њ–њ—В–Є–Љ–Є–Ј–∞—Ж–Є–Є, –Ш–Ш (data science, —Б—В–∞—В–Є—Б—В–Є–Ї–∞, —Н–Ї–Њ–љ–Њ–Љ–µ—В—А–Є–Ї–∞), —Г–њ—А–∞–≤–ї–µ–љ–Є–µ –і–∞–љ–љ—Л–Љ (data governance), DB –Є BI. –°–љ–∞—З–∞–ї–∞ –Њ–њ–Є—Б–∞–љ–Є–µ –њ—А–Њ—Ж–µ—Б—Б–Њ–≤ —Д–Њ—А–Љ–∞–ї–Є–Ј—Г–µ—В—Б—П —Б –њ–Њ–Љ–Њ—Й—М—О —Д–Њ—А–Љ—Г–ї. –Ф–∞—В–∞-—Б–∞–є–љ—В–Є—Б—В—Л –љ–∞—Е–Њ–і—П—В –Ј–∞–Ї–Њ–љ–Њ–Љ–µ—А–љ–Њ—Б—В–Є –Є –њ—Л—В–∞—О—В—Б—П –≤—Л—Б—В—А–Њ–Є—В—М –Љ–∞—В–µ–Љ–∞—В–Є—З–µ—Б–Ї—Г—О –Ј–∞–≤–Є—Б–Є–Љ–Њ—Б—В—М, –Є–Ј –Ї–Њ—В–Њ—А–Њ–є –±—Г–і–µ—В —Б—Д–Њ—А–Љ–Є—А–Њ–≤–∞–љ –љ–∞–±–Њ—А –∞–ї—М—В–µ—А–љ–∞—В–Є–≤. –†–µ—И–∞—П –Ј–∞–і–∞—З—Г –Њ–њ—В–Є–Љ–Є–Ј–∞—Ж–Є–Є, –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–Є –±—Г–і—Г—В –≤—Л–±–Є—А–∞—В—М –∞–ї—М—В–µ—А–љ–∞—В–Є–≤—Г –Є–Ј —Н—В–Њ–≥–Њ –љ–∞–±–Њ—А–∞.
Decision intelligence –љ–µ –њ—А–µ–і–љ–∞–Ј–љ–∞—З–µ–љ–∞ –і–ї—П —В–Њ–≥–Њ, —З—В–Њ–±—Л –Ј–∞–Љ–µ–љ–Є—В—М —З–µ–ї–Њ–≤–µ–Ї–∞. –Ю–љ–∞ –Њ–Ї–∞–Ј—Л–≤–∞–µ—В –њ–Њ–Љ–Њ—Й—М –≤ –њ—А–Є–љ—П—В–Є–Є —А–µ—И–µ–љ–Є—П –Є –Љ–Њ–ґ–µ—В –њ–Њ–≤—Л—Б–Є—В—М –µ–≥–Њ —Н—Д—Д–µ–Ї—В–Є–≤–љ–Њ—Б—В—М. –Ю–њ—Л—В, –Є–љ—В—Г–Є—Ж–Є—О –Є –Ј–љ–∞–љ–Є—П —З–µ–ї–Њ–≤–µ–Ї–∞ –Ј–∞–Љ–µ–љ–Є—В—М –љ–µ–ї—М–Ј—П, –∞ –≤–Њ—В –њ—А–µ–і–Њ—Б—В–∞–≤–Є—В—М –µ–Љ—Г –љ–Њ–≤—Л–µ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В–Є –і–ї—П –Њ–±—А–∞–±–Њ—В–Ї–Є –Љ–љ–Њ–≥–Њ–Љ–µ—А–љ—Л—Е –Є –±–Њ–ї—М—И–Є—Е –і–∞–љ–љ—Л—Е –Љ–Њ–ґ–љ–Њ. ¬Ђ–Ъ–Њ–≥–і–∞ —Б—З–Є—В–∞–µ—В—Б—П, —З—В–Њ –≤—Б–µ –Љ–Њ–ґ–љ–Њ –Њ—Ж–Є—Д—А–Њ–≤–∞—В—М вАФ —Н—В–Њ –Љ–∞—В–µ–Љ–∞—В–Є—З–µ—Б–Ї–Є–є —Н–Ї—Б—В—А–µ–Љ–Є–Ј–Љ, —Д–∞–љ–∞—В–Є–Ј–Љ –Є –љ–µ–≤–µ–ґ–µ—Б—В–≤–Њ. –Э–µ –≤—Б–µ –Љ–Њ–ґ–љ–Њ –Њ—Ж–Є—Д—А–Њ–≤–∞—В—М, –љ–µ –≤—Б–µ –Љ–Њ–ґ–љ–Њ —Б–Љ–Њ–і–µ–ї–Є—А–Њ–≤–∞—В—М –Є –љ–µ –≤—Б–µ —Б–ї–µ–і—Г–µ—В –≤–∞–ї–Є—В—М –љ–∞ –Љ–∞—В–µ–Љ–∞—В–Є–Ї–∞. –≠–Ї—Б–њ–µ—А—В—Г —В–Њ–ґ–µ –љ–∞–і–Њ –њ—А–Є–љ–Є–Љ–∞—В—М —А–µ—И–µ–љ–Є—П. –≠–Ї—Б–њ–µ—А—В вАФ —Н—В–Њ –Њ—З–µ–љ—М –≤–∞–ґ–љ–Њ. Big Data –Є Data Driven вАФ —В–µ—А–Љ–Є–љ—Л —Е–∞–є–њ–∞. –Ф–∞–љ–љ—Л–µ —Б–∞–Љ–Є –њ–Њ —Б–µ–±–µ –љ–µ –Є–Љ–µ—О—В —Ж–µ–љ–љ–Њ—Б—В–Є, —Н—В–Њ —Ж–µ–љ—В—А –Ј–∞—В—А–∞—В. –¶–µ–љ–љ–Њ—Б—В—М –і–∞–љ–љ—Л—Е –њ–Њ—П–≤–ї—П–µ—В—Б—П —В–Њ–ї—М–Ї–Њ —В–Њ–≥–і–∞, –Ї–Њ–≥–і–∞ –Љ—Л –Є—Е –њ—А–Њ–∞–љ–∞–ї–Є–Ј–Є—А–Њ–≤–∞–ї–Є –Є –њ—А–Є–Љ–µ–љ–Є–ї–Є –і–ї—П –Є–Ј–Љ–µ–љ–µ–љ–Є—П –±–Є–Ј–љ–µ—Б-–њ—А–Њ—Ж–µ—Б—Б–Њ–≤¬ї, вАФ –њ–Њ–і—З–µ—А–Ї–љ—Г–ї –і–Њ–Ї–ї–∞–і—З–Є–Ї.
 –Ґ–Њ–љ —Д–Њ—А—Г–Љ—Г –Ј–∞–і–∞–ї–Њ –Њ—В–Ї—А—Л—В–Њ–µ –Є–љ—В–µ—А–≤—М—О –≥–ї–∞–≤—Л –Ь–Є–љ—Ж–Є—Д—А—Л –Ь–∞–Ї—Б—Г—В–∞ –®–∞–і–∞–µ–≤–∞ –≥–ї–∞–≤–љ–Њ–Љ—Г —А–µ–і–∞–Ї—В–Њ—А—Г CNews –Р–ї–µ–Ї—Б–∞–љ–і—А–µ –Ъ–Є—А—М—П–љ–Њ–≤–Њ–є
–Ґ–Њ–љ —Д–Њ—А—Г–Љ—Г –Ј–∞–і–∞–ї–Њ –Њ—В–Ї—А—Л—В–Њ–µ –Є–љ—В–µ—А–≤—М—О –≥–ї–∞–≤—Л –Ь–Є–љ—Ж–Є—Д—А—Л –Ь–∞–Ї—Б—Г—В–∞ –®–∞–і–∞–µ–≤–∞ –≥–ї–∞–≤–љ–Њ–Љ—Г —А–µ–і–∞–Ї—В–Њ—А—Г CNews –Р–ї–µ–Ї—Б–∞–љ–і—А–µ –Ъ–Є—А—М—П–љ–Њ–≤–Њ–є
 –Я—А—П–Љ–∞—П —В—А–∞–љ—Б–ї—П—Ж–Є—П –Є–љ—В–µ—А–≤—М—О –Љ–Є–љ–Є—Б—В—А–∞ —И–ї–∞ –≤ –Є–љ—В–µ—А–љ–µ—В–µ
–Я—А—П–Љ–∞—П —В—А–∞–љ—Б–ї—П—Ж–Є—П –Є–љ—В–µ—А–≤—М—О –Љ–Є–љ–Є—Б—В—А–∞ —И–ї–∞ –≤ –Є–љ—В–µ—А–љ–µ—В–µ
 –Э–∞ —Д–Њ—А—Г–Љ–∞—Е CNews –≤ –Ј–∞–ї–µ —В—А–∞–і–Є—Ж–Є–Њ–љ–љ–Њ –љ–µ—В —Б–≤–Њ–±–Њ–і–љ—Л—Е –Љ–µ—Б—В
–Э–∞ —Д–Њ—А—Г–Љ–∞—Е CNews –≤ –Ј–∞–ї–µ —В—А–∞–і–Є—Ж–Є–Њ–љ–љ–Њ –љ–µ—В —Б–≤–Њ–±–Њ–і–љ—Л—Е –Љ–µ—Б—В
 –Э–∞–≥—А–∞–і—Г CNews –≤ –љ–Њ–Љ–Є–љ–∞—Ж–Є–Є ¬Ђ–Ш–Љ–њ–Њ—А—В–Њ–Ј–∞–Љ–µ—Й–µ–љ–Є–µ –≥–Њ–і–∞ –≤ —Б–Є—Б—В–µ–Љ–∞—Е —Г–њ—А–∞–≤–ї–µ–љ–Є—П –Ш–Ґ-–Є–љ—Д—А–∞—Б—В—А—Г–Ї—В—Г—А–Њ–є¬ї –њ–Њ–ї—Г—З–Є–ї–Є –њ—А–µ–і—Б—В–∞–≤–Є—В–µ–ї–Є –Ї–Њ–Љ–њ–∞–љ–Є–Є ¬Ђ–У–µ–ї–∞—А–Љ¬ї
–Э–∞–≥—А–∞–і—Г CNews –≤ –љ–Њ–Љ–Є–љ–∞—Ж–Є–Є ¬Ђ–Ш–Љ–њ–Њ—А—В–Њ–Ј–∞–Љ–µ—Й–µ–љ–Є–µ –≥–Њ–і–∞ –≤ —Б–Є—Б—В–µ–Љ–∞—Е —Г–њ—А–∞–≤–ї–µ–љ–Є—П –Ш–Ґ-–Є–љ—Д—А–∞—Б—В—А—Г–Ї—В—Г—А–Њ–є¬ї –њ–Њ–ї—Г—З–Є–ї–Є –њ—А–µ–і—Б—В–∞–≤–Є—В–µ–ї–Є –Ї–Њ–Љ–њ–∞–љ–Є–Є ¬Ђ–У–µ–ї–∞—А–Љ¬ї
 –У–µ–љ–µ—А–∞–ї—М–љ—Л–є –і–Є—А–µ–Ї—В–Њ—А Delta Computers –Р–љ–і—А–µ–є –І–µ—А–љ—Л—И–µ–≤ –≤—Л—Б—В—Г–њ–Є–ї —Б –і–Њ–Ї–ї–∞–і–Њ–Љ –љ–∞ —В–µ–Љ—Г –њ–µ—А–µ—Е–Њ–і–∞ –љ–∞ –Њ—В–µ—З–µ—Б—В–≤–µ–љ–љ—Л–µ —А–µ—И–µ–љ–Є—П –і–ї—П –Ш–Ґ-–Є–љ—Д—А–∞—Б—В—А—Г–Ї—В—Г—А—Л
–У–µ–љ–µ—А–∞–ї—М–љ—Л–є –і–Є—А–µ–Ї—В–Њ—А Delta Computers –Р–љ–і—А–µ–є –І–µ—А–љ—Л—И–µ–≤ –≤—Л—Б—В—Г–њ–Є–ї —Б –і–Њ–Ї–ї–∞–і–Њ–Љ –љ–∞ —В–µ–Љ—Г –њ–µ—А–µ—Е–Њ–і–∞ –љ–∞ –Њ—В–µ—З–µ—Б—В–≤–µ–љ–љ—Л–µ —А–µ—И–µ–љ–Є—П –і–ї—П –Ш–Ґ-–Є–љ—Д—А–∞—Б—В—А—Г–Ї—В—Г—А—Л
 –Э–∞—З–∞–ї—М–љ–Є–Ї —Г–њ—А–∞–≤–ї–µ–љ–Є—П –Ш–Ґ ¬Ђ–°—Г—А–≥—Г—В–љ–µ—Д—В–µ–≥–∞–Ј–∞¬ї –†–Є–љ–∞—В –У–Є–Љ—А–∞–љ–Њ–≤ —В–µ–Њ—А–µ—В–Є–Ј–Є—А–Њ–≤–∞–ї –Њ–± –Њ—Б–Њ–±–µ–љ–љ–Њ—Б—В–Є –Ш–Ґ-—Б—В—А–∞—В–µ–≥–Є–Є –Ї—А—Г–њ–љ–Њ–є –Ї–Њ–Љ–њ–∞–љ–Є–Є –љ–∞ —Б–Њ–≤—А–µ–Љ–µ–љ–љ–Њ–Љ —Н—В–∞–њ–µ
–Э–∞—З–∞–ї—М–љ–Є–Ї —Г–њ—А–∞–≤–ї–µ–љ–Є—П –Ш–Ґ ¬Ђ–°—Г—А–≥—Г—В–љ–µ—Д—В–µ–≥–∞–Ј–∞¬ї –†–Є–љ–∞—В –У–Є–Љ—А–∞–љ–Њ–≤ —В–µ–Њ—А–µ—В–Є–Ј–Є—А–Њ–≤–∞–ї –Њ–± –Њ—Б–Њ–±–µ–љ–љ–Њ—Б—В–Є –Ш–Ґ-—Б—В—А–∞—В–µ–≥–Є–Є –Ї—А—Г–њ–љ–Њ–є –Ї–Њ–Љ–њ–∞–љ–Є–Є –љ–∞ —Б–Њ–≤—А–µ–Љ–µ–љ–љ–Њ–Љ —Н—В–∞–њ–µ
 –†—Г–Ї–Њ–≤–Њ–і–Є—В–µ–ї—М –і–Є—А–µ–Ї—Ж–Є–Є –њ–Њ –Є–љ–љ–Њ–≤–∞—Ж–Є–Њ–љ–љ–Њ–є –і–µ—П—В–µ–ї—М–љ–Њ—Б—В–Є –Є –Є–Љ–њ–Њ—А—В–Њ–Ј–∞–Љ–µ—Й–µ–љ–Є—О –Ї–Њ–Љ–њ–∞–љ–Є–Є ¬Ђ–†–Њ—Б—Б–µ—В–Є —Ж–µ–љ—В—А¬ї –Т–∞–ї–µ—А–Є–є –Ь–Є–Ї—А—О–Ї–Њ–≤ –њ—А–Є–љ—П–ї –љ–∞–≥—А–∞–і—Г –≤ –љ–Њ–Љ–Є–љ–∞—Ж–Є–Є ¬Ђ–¶–Є—Д—А–Њ–≤—Л–µ –і–≤–Њ–є–љ–Є–Ї–Є: –њ—А–Њ–µ–Ї—В –≥–Њ–і–∞¬ї
–†—Г–Ї–Њ–≤–Њ–і–Є—В–µ–ї—М –і–Є—А–µ–Ї—Ж–Є–Є –њ–Њ –Є–љ–љ–Њ–≤–∞—Ж–Є–Њ–љ–љ–Њ–є –і–µ—П—В–µ–ї—М–љ–Њ—Б—В–Є –Є –Є–Љ–њ–Њ—А—В–Њ–Ј–∞–Љ–µ—Й–µ–љ–Є—О –Ї–Њ–Љ–њ–∞–љ–Є–Є ¬Ђ–†–Њ—Б—Б–µ—В–Є —Ж–µ–љ—В—А¬ї –Т–∞–ї–µ—А–Є–є –Ь–Є–Ї—А—О–Ї–Њ–≤ –њ—А–Є–љ—П–ї –љ–∞–≥—А–∞–і—Г –≤ –љ–Њ–Љ–Є–љ–∞—Ж–Є–Є ¬Ђ–¶–Є—Д—А–Њ–≤—Л–µ –і–≤–Њ–є–љ–Є–Ї–Є: –њ—А–Њ–µ–Ї—В –≥–Њ–і–∞¬ї
 –Ф–Є—А–µ–Ї—В–Њ—А –њ–Њ —А–∞–Ј–≤–Є—В–Є—О –Ї–Њ—А–њ–Њ—А–∞—В–Є–≤–љ–Њ–≥–Њ –±–Є–Ј–љ–µ—Б–∞ ¬Ђ–Ь–µ–≥–∞—Д–Њ–љ–∞¬ї –≤ —А–µ–≥–Є–Њ–љ–µ ¬Ђ–°—В–Њ–ї–Є—Ж–∞¬ї –Р–ї–µ–Ї—Б–∞–љ–і—А –®–Є–љ–Ї–∞—А–µ–≤ —А–∞—Б—Б–Ї–∞–Ј–∞–ї –Њ–± –∞–Ї—В—Г–∞–ї—М–љ—Л—Е —А–µ—И–µ–љ–Є—П—Е –і–ї—П –њ–Њ–і–і–µ—А–ґ–Ї–Є –Є —А–∞–Ј–≤–Є—В–Є—П –±–Є–Ј–љ–µ—Б–∞
–Ф–Є—А–µ–Ї—В–Њ—А –њ–Њ —А–∞–Ј–≤–Є—В–Є—О –Ї–Њ—А–њ–Њ—А–∞—В–Є–≤–љ–Њ–≥–Њ –±–Є–Ј–љ–µ—Б–∞ ¬Ђ–Ь–µ–≥–∞—Д–Њ–љ–∞¬ї –≤ —А–µ–≥–Є–Њ–љ–µ ¬Ђ–°—В–Њ–ї–Є—Ж–∞¬ї –Р–ї–µ–Ї—Б–∞–љ–і—А –®–Є–љ–Ї–∞—А–µ–≤ —А–∞—Б—Б–Ї–∞–Ј–∞–ї –Њ–± –∞–Ї—В—Г–∞–ї—М–љ—Л—Е —А–µ—И–µ–љ–Є—П—Е –і–ї—П –њ–Њ–і–і–µ—А–ґ–Ї–Є –Є —А–∞–Ј–≤–Є—В–Є—П –±–Є–Ј–љ–µ—Б–∞
 –Ф–Є—А–µ–Ї—В–Њ—А –і–µ–њ–∞—А—В–∞–Љ–µ–љ—В–∞ –Ш–Ґ ¬Ђ–£—А–∞–ї—Е–Є–Љ–∞¬ї –Т–∞–ї–µ—А–Є–є –§–Њ–Ї–Є–љ –њ–Њ–і–µ–ї–Є–ї—Б—П –Љ—Л—Б–ї—П–Љ–Є –Њ —В–Њ–Љ, –Ї–∞–Ї —А–∞–Ј—А–∞–±–Њ—В–∞—В—М —Ж–Є—Д—А–Њ–≤—Г—О —Б—В—А–∞—В–µ–≥–Є—О
–Ф–Є—А–µ–Ї—В–Њ—А –і–µ–њ–∞—А—В–∞–Љ–µ–љ—В–∞ –Ш–Ґ ¬Ђ–£—А–∞–ї—Е–Є–Љ–∞¬ї –Т–∞–ї–µ—А–Є–є –§–Њ–Ї–Є–љ –њ–Њ–і–µ–ї–Є–ї—Б—П –Љ—Л—Б–ї—П–Љ–Є –Њ —В–Њ–Љ, –Ї–∞–Ї —А–∞–Ј—А–∞–±–Њ—В–∞—В—М —Ж–Є—Д—А–Њ–≤—Г—О —Б—В—А–∞—В–µ–≥–Є—О
 –Э–∞–≥—А–∞–і—Г –≤ –љ–Њ–Љ–Є–љ–∞—Ж–Є–Є ¬Ђ–Ш–Љ–њ–Њ—А—В–Њ–Ј–∞–Љ–µ—Й–µ–љ–Є–µ 2022: Low-code –њ–ї–∞—В—Д–Њ—А–Љ–∞ –≥–Њ–і–∞¬ї –њ–Њ–ї—Г—З–Є–ї–Є –њ—А–µ–і—Б—В–∞–≤–Є—В–µ–ї–Є Manage.one
–Э–∞–≥—А–∞–і—Г –≤ –љ–Њ–Љ–Є–љ–∞—Ж–Є–Є ¬Ђ–Ш–Љ–њ–Њ—А—В–Њ–Ј–∞–Љ–µ—Й–µ–љ–Є–µ 2022: Low-code –њ–ї–∞—В—Д–Њ—А–Љ–∞ –≥–Њ–і–∞¬ї –њ–Њ–ї—Г—З–Є–ї–Є –њ—А–µ–і—Б—В–∞–≤–Є—В–µ–ї–Є Manage.one
 –Я–µ—А–≤—Л–є –≤–Є—Ж–µ-–њ—А–µ–Ј–Є–і–µ–љ—В –њ–Њ —В–µ—Е–љ–Њ–ї–Њ–≥–Є—П–Љ –Ь–Ґ–° –Я–∞–≤–µ–ї –Т–Њ—А–Њ–љ–Є–љ –Њ–њ–Є—Б–∞–ї –Њ—Б–Њ–±–µ–љ–љ–Њ—Б—В–Є —Г–њ—А–∞–≤–ї–µ–љ–Є—П —В–µ—Е–љ–Њ–ї–Њ–≥–Є—П–Љ–Є –≤ —Н–Ї–Њ—Б–Є—Б—В–µ–Љ–љ–Њ–є –Ї–Њ–Љ–њ–∞–љ–Є–Є
–Я–µ—А–≤—Л–є –≤–Є—Ж–µ-–њ—А–µ–Ј–Є–і–µ–љ—В –њ–Њ —В–µ—Е–љ–Њ–ї–Њ–≥–Є—П–Љ –Ь–Ґ–° –Я–∞–≤–µ–ї –Т–Њ—А–Њ–љ–Є–љ –Њ–њ–Є—Б–∞–ї –Њ—Б–Њ–±–µ–љ–љ–Њ—Б—В–Є —Г–њ—А–∞–≤–ї–µ–љ–Є—П —В–µ—Е–љ–Њ–ї–Њ–≥–Є—П–Љ–Є –≤ —Н–Ї–Њ—Б–Є—Б—В–µ–Љ–љ–Њ–є –Ї–Њ–Љ–њ–∞–љ–Є–Є
 –Т—Л—Б—В—Г–њ–ї–µ–љ–Є—П –±–Њ–ї—М—И–Є–љ—Б—В–≤–∞ —Б–њ–Є–Ї–µ—А–Њ–≤ —Б–Њ–њ—А–Њ–≤–Њ–ґ–і–∞–ї–Є—Б—М –њ–Њ–Ї–∞–Ј–Њ–Љ —Н–ї–µ–Ї—В—А–Њ–љ–љ—Л—Е –њ—А–µ–Ј–µ–љ—В–∞—Ж–Є–є, —Б–ї–∞–є–і—Л –Ї–Њ—В–Њ—А—Л—Е –≤—Л–Ј—Л–≤–∞–ї–Є —П–≤–љ—Л–є –Є–љ—В–µ—А–µ—Б –∞—Г–і–Є—В–Њ—А–Є–Є
–Т—Л—Б—В—Г–њ–ї–µ–љ–Є—П –±–Њ–ї—М—И–Є–љ—Б—В–≤–∞ —Б–њ–Є–Ї–µ—А–Њ–≤ —Б–Њ–њ—А–Њ–≤–Њ–ґ–і–∞–ї–Є—Б—М –њ–Њ–Ї–∞–Ј–Њ–Љ —Н–ї–µ–Ї—В—А–Њ–љ–љ—Л—Е –њ—А–µ–Ј–µ–љ—В–∞—Ж–Є–є, —Б–ї–∞–є–і—Л –Ї–Њ—В–Њ—А—Л—Е –≤—Л–Ј—Л–≤–∞–ї–Є —П–≤–љ—Л–є –Є–љ—В–µ—А–µ—Б –∞—Г–і–Є—В–Њ—А–Є–Є
 –Ш—Б–њ–Њ–ї–љ–Є—В–µ–ї—М–љ—Л–є –і–Є—А–µ–Ї—В–Њ—А –Ї–Њ–Љ–њ–∞–љ–Є–Є Directum –Ъ–Њ–љ—Б—В–∞–љ—В–Є–љ –Ш—Б—В–Њ–Љ–Є–љ –њ—А–µ–і—Б—В–∞–≤–Є–ї –і–Њ–Ї–ї–∞–і –љ–∞ —В–µ–Љ—Г ¬Ђ–Я–µ—А–µ—Е–Њ–і—П вАФ –њ–µ—А–µ—Е–Њ–і–Є: —Ж–Є—Д—А–Њ–≤–Є–Ј–∞—Ж–Є—П –±–Є–Ј–љ–µ—Б-–њ—А–Њ—Ж–µ—Б—Б–Њ–≤ –≤ –љ–Њ–≤—Л—Е —Г—Б–ї–Њ–≤–Є—П—Е¬ї
–Ш—Б–њ–Њ–ї–љ–Є—В–µ–ї—М–љ—Л–є –і–Є—А–µ–Ї—В–Њ—А –Ї–Њ–Љ–њ–∞–љ–Є–Є Directum –Ъ–Њ–љ—Б—В–∞–љ—В–Є–љ –Ш—Б—В–Њ–Љ–Є–љ –њ—А–µ–і—Б—В–∞–≤–Є–ї –і–Њ–Ї–ї–∞–і –љ–∞ —В–µ–Љ—Г ¬Ђ–Я–µ—А–µ—Е–Њ–і—П вАФ –њ–µ—А–µ—Е–Њ–і–Є: —Ж–Є—Д—А–Њ–≤–Є–Ј–∞—Ж–Є—П –±–Є–Ј–љ–µ—Б-–њ—А–Њ—Ж–µ—Б—Б–Њ–≤ –≤ –љ–Њ–≤—Л—Е —Г—Б–ї–Њ–≤–Є—П—Е¬ї
 –Ф–Є—А–µ–Ї—В–Њ—А –њ–Њ –Ш–Ґ, —З–ї–µ–љ –њ—А–∞–≤–ї–µ–љ–Є—П ¬Ђ–Э–∞—Ж–Є–Њ–љ–∞–ї—М–љ–Њ–≥–Њ —А–∞—Б—З–µ—В–љ–Њ–≥–Њ –і–µ–њ–Њ–Ј–Є—В–∞—А–Є—П –Я–∞–≤–µ–ї –Р–љ–і—А–Є–∞–љ–Њ–≤ —А–∞—Б—Б–Ї–∞–Ј–∞–ї –Њ–± –Њ–њ—Л—В–µ —Б–≤–Њ–µ–є –Њ—А–≥–∞–љ–Є–Ј–∞—Ж–Є–Є –≤ –Є–Љ–њ–Њ—А—В–Њ–Ј–∞–Љ–µ—Й–µ–љ–Є–Є
–Ф–Є—А–µ–Ї—В–Њ—А –њ–Њ –Ш–Ґ, —З–ї–µ–љ –њ—А–∞–≤–ї–µ–љ–Є—П ¬Ђ–Э–∞—Ж–Є–Њ–љ–∞–ї—М–љ–Њ–≥–Њ —А–∞—Б—З–µ—В–љ–Њ–≥–Њ –і–µ–њ–Њ–Ј–Є—В–∞—А–Є—П –Я–∞–≤–µ–ї –Р–љ–і—А–Є–∞–љ–Њ–≤ —А–∞—Б—Б–Ї–∞–Ј–∞–ї –Њ–± –Њ–њ—Л—В–µ —Б–≤–Њ–µ–є –Њ—А–≥–∞–љ–Є–Ј–∞—Ж–Є–Є –≤ –Є–Љ–њ–Њ—А—В–Њ–Ј–∞–Љ–µ—Й–µ–љ–Є–Є
 –†—Г–Ї–Њ–≤–Њ–і–Є—В–µ–ї—М –њ—А–Њ–і—Г–Ї—В–∞ ¬Ђ–Ъ–Њ—А–њ–Њ—А–∞—В–Є–≤–љ–∞—П —И–Є–љ–∞ –і–∞–љ–љ—Л—Е UseBus¬ї –≥—А—Г–њ–њ—Л ¬Ђ–Ѓ–Ј—В–µ—Е¬ї –Я–∞–≤–µ–ї –Х—А–Њ—И–Ї–Є–љ –њ–Њ–ї—Г—З–Є–ї –љ–∞–≥—А–∞–і—Г –≤ –љ–Њ–Љ–Є–љ–∞—Ж–Є–Є ¬Ђ–Ш–Љ–њ–Њ—А—В–Њ–Ј–∞–Љ–µ—Й–µ–љ–Є–µ –≥–Њ–і–∞ –≤ –Є–љ—В–µ–≥—А–∞—Ж–Є–Є –њ—А–Є–ї–Њ–ґ–µ–љ–Є–є¬ї
–†—Г–Ї–Њ–≤–Њ–і–Є—В–µ–ї—М –њ—А–Њ–і—Г–Ї—В–∞ ¬Ђ–Ъ–Њ—А–њ–Њ—А–∞—В–Є–≤–љ–∞—П —И–Є–љ–∞ –і–∞–љ–љ—Л—Е UseBus¬ї –≥—А—Г–њ–њ—Л ¬Ђ–Ѓ–Ј—В–µ—Е¬ї –Я–∞–≤–µ–ї –Х—А–Њ—И–Ї–Є–љ –њ–Њ–ї—Г—З–Є–ї –љ–∞–≥—А–∞–і—Г –≤ –љ–Њ–Љ–Є–љ–∞—Ж–Є–Є ¬Ђ–Ш–Љ–њ–Њ—А—В–Њ–Ј–∞–Љ–µ—Й–µ–љ–Є–µ –≥–Њ–і–∞ –≤ –Є–љ—В–µ–≥—А–∞—Ж–Є–Є –њ—А–Є–ї–Њ–ґ–µ–љ–Є–є¬ї
 –Т–Є—Ж–µ-–њ—А–µ–Ј–Є–і–µ–љ—В –њ–Њ –Ш–Ґ ¬Ђ–Х–≤—А–∞–Ј–∞¬ї –Р—А—В–µ–Љ –Э–∞—В—А—Г—Б–Њ–≤ —А–∞–Ј–Њ–±—А–∞–ї –Ї–µ–є—Б—Л —Б–≤–Њ–µ–є –Ї–Њ–Љ–њ–∞–љ–Є–Є, –Њ–њ–Є—Б–∞–≤ —Н–Ї–Њ–љ–Њ–Љ–Є—З–µ—Б–Ї–Є–є —Н—Д—Д–µ–Ї—В –Є —Ж–µ–ї–µ–≤–Њ–є –≤–Є–і–µ–љ–Є–µ —Ж–Є—Д—А–Њ–≤–Є–Ј–∞—Ж–Є–Є
–Т–Є—Ж–µ-–њ—А–µ–Ј–Є–і–µ–љ—В –њ–Њ –Ш–Ґ ¬Ђ–Х–≤—А–∞–Ј–∞¬ї –Р—А—В–µ–Љ –Э–∞—В—А—Г—Б–Њ–≤ —А–∞–Ј–Њ–±—А–∞–ї –Ї–µ–є—Б—Л —Б–≤–Њ–µ–є –Ї–Њ–Љ–њ–∞–љ–Є–Є, –Њ–њ–Є—Б–∞–≤ —Н–Ї–Њ–љ–Њ–Љ–Є—З–µ—Б–Ї–Є–є —Н—Д—Д–µ–Ї—В –Є —Ж–µ–ї–µ–≤–Њ–є –≤–Є–і–µ–љ–Є–µ —Ж–Є—Д—А–Њ–≤–Є–Ј–∞—Ж–Є–Є
 –Э–∞–≥—А–∞–і–∞ –≤ –љ–Њ–Љ–Є–љ–∞—Ж–Є–Є ¬Ђ–Ш–љ–љ–Њ–≤–∞—Ж–Є—П –≥–Њ–і–∞ –љ–∞ —А—Л–љ–Ї–µ –Є–љ—Д–Њ—А–Љ–∞—Ж–Є–Њ–љ–љ–Њ–є –±–µ–Ј–Њ–њ–∞—Б–љ–Њ—Б—В–Є¬ї –±—Л–ї–∞ –≤—А—Г—З–µ–љ–∞ –≤–Є—Ж–µ-–њ—А–µ–Ј–Є–і–µ–љ—В—Г –њ–Њ –Љ–∞—А–Ї–µ—В–Є–љ–≥—Г –Є —А–∞–Ј–≤–Є—В–Є—О –њ—А–Њ–і—Г–Ї—В–Њ–≤ –≥—А—Г–њ–њ—Л InfoWatch –Ь–∞—А–≥–∞—А–Є—В–µ –Р–Љ–∞–ї–Є—Ж–Ї–Њ–є
–Э–∞–≥—А–∞–і–∞ –≤ –љ–Њ–Љ–Є–љ–∞—Ж–Є–Є ¬Ђ–Ш–љ–љ–Њ–≤–∞—Ж–Є—П –≥–Њ–і–∞ –љ–∞ —А—Л–љ–Ї–µ –Є–љ—Д–Њ—А–Љ–∞—Ж–Є–Њ–љ–љ–Њ–є –±–µ–Ј–Њ–њ–∞—Б–љ–Њ—Б—В–Є¬ї –±—Л–ї–∞ –≤—А—Г—З–µ–љ–∞ –≤–Є—Ж–µ-–њ—А–µ–Ј–Є–і–µ–љ—В—Г –њ–Њ –Љ–∞—А–Ї–µ—В–Є–љ–≥—Г –Є —А–∞–Ј–≤–Є—В–Є—О –њ—А–Њ–і—Г–Ї—В–Њ–≤ –≥—А—Г–њ–њ—Л InfoWatch –Ь–∞—А–≥–∞—А–Є—В–µ –Р–Љ–∞–ї–Є—Ж–Ї–Њ–є
 –°—В–∞—А—И–Є–є –≤–Є—Ж–µ-–њ—А–µ–Ј–Є–і–µ–љ—В –њ–Њ –±–∞–љ–Ї–Њ–≤—Б–Ї–Є–Љ —В–µ—Е–љ–Њ–ї–Њ–≥–Є—П–Љ –±–∞–љ–Ї–∞ ¬Ђ–£—А–∞–ї—Б–Є–±¬ї –Ъ–Њ–љ—Б—В–∞–љ—В–Є–љ –Ь–µ–і–µ–љ—Ж–µ–≤ –≤—Л—Б—В—Г–њ–Є–ї —Б –і–Њ–Ї–ї–∞–і–Њ–Љ –љ–∞ —В–µ–Љ—Г ¬Ђ–Ъ–Њ–≥–і–∞ –Є–Ј–Љ–µ–љ–µ–љ–Є—П –љ–µ–Є–Ј–±–µ–ґ–љ—Л: —А–Њ–ї—М –Ш–Ґ –≤ —В—А–∞–љ—Б—Д–Њ—А–Љ–∞—Ж–Є—П –±–Є–Ј–љ–µ—Б–∞ –±–∞–љ–Ї–∞¬ї
–°—В–∞—А—И–Є–є –≤–Є—Ж–µ-–њ—А–µ–Ј–Є–і–µ–љ—В –њ–Њ –±–∞–љ–Ї–Њ–≤—Б–Ї–Є–Љ —В–µ—Е–љ–Њ–ї–Њ–≥–Є—П–Љ –±–∞–љ–Ї–∞ ¬Ђ–£—А–∞–ї—Б–Є–±¬ї –Ъ–Њ–љ—Б—В–∞–љ—В–Є–љ –Ь–µ–і–µ–љ—Ж–µ–≤ –≤—Л—Б—В—Г–њ–Є–ї —Б –і–Њ–Ї–ї–∞–і–Њ–Љ –љ–∞ —В–µ–Љ—Г ¬Ђ–Ъ–Њ–≥–і–∞ –Є–Ј–Љ–µ–љ–µ–љ–Є—П –љ–µ–Є–Ј–±–µ–ґ–љ—Л: —А–Њ–ї—М –Ш–Ґ –≤ —В—А–∞–љ—Б—Д–Њ—А–Љ–∞—Ж–Є—П –±–Є–Ј–љ–µ—Б–∞ –±–∞–љ–Ї–∞¬ї
 –І–ї–µ–љ –њ—А–∞–≤–ї–µ–љ–Є—П, —Б—В–∞—А—И–Є–є –≤–Є—Ж–µ-–њ—А–µ–Ј–Є–і–µ–љ—В –њ–Њ –Ш–Ґ –Є —Ж–Є—Д—А–Њ–≤–Њ–є —В—А–∞–љ—Б—Д–Њ—А–Љ–∞—Ж–Є–Є –±–Є–Ј–љ–µ—Б–∞ –±–∞–љ–Ї–∞ ¬Ђ–†–µ–љ–µ—Б—Б–∞–љ—Б –Ї—А–µ–і–Є—В¬ї –Ф–µ–љ–Є—Б –°–Њ—В–Є–љ —А–∞—Б—Б–Ї–∞–Ј–∞–ї –Њ –њ—А–Є–Њ—А–Є—В–µ—В–∞—Е —В–µ—Е–љ–Њ–ї–Њ–≥–Є—З–µ—Б–Ї–Њ–≥–Њ —А–∞–Ј–≤–Є—В–Є—П —Б–≤–Њ–µ–є –Њ—А–≥–∞–љ–Є–Ј–∞—Ж–Є–Є –≤ —Г—Б–ї–Њ–≤–Є—П—Е –Є–Ј–Љ–µ–љ—П—О—Й–µ–≥–Њ –Њ–Ї—А—Г–ґ–µ–љ–Є—П
–І–ї–µ–љ –њ—А–∞–≤–ї–µ–љ–Є—П, —Б—В–∞—А—И–Є–є –≤–Є—Ж–µ-–њ—А–µ–Ј–Є–і–µ–љ—В –њ–Њ –Ш–Ґ –Є —Ж–Є—Д—А–Њ–≤–Њ–є —В—А–∞–љ—Б—Д–Њ—А–Љ–∞—Ж–Є–Є –±–Є–Ј–љ–µ—Б–∞ –±–∞–љ–Ї–∞ ¬Ђ–†–µ–љ–µ—Б—Б–∞–љ—Б –Ї—А–µ–і–Є—В¬ї –Ф–µ–љ–Є—Б –°–Њ—В–Є–љ —А–∞—Б—Б–Ї–∞–Ј–∞–ї –Њ –њ—А–Є–Њ—А–Є—В–µ—В–∞—Е —В–µ—Е–љ–Њ–ї–Њ–≥–Є—З–µ—Б–Ї–Њ–≥–Њ —А–∞–Ј–≤–Є—В–Є—П —Б–≤–Њ–µ–є –Њ—А–≥–∞–љ–Є–Ј–∞—Ж–Є–Є –≤ —Г—Б–ї–Њ–≤–Є—П—Е –Є–Ј–Љ–µ–љ—П—О—Й–µ–≥–Њ –Њ–Ї—А—Г–ґ–µ–љ–Є—П
 –Ф–Є—А–µ–Ї—В–Њ—А –њ–Њ –Ш–Ґ ¬Ђ–†–Њ—Б–±–∞–љ–Ї–∞¬ї –Р–ї–µ–Ї—Б–∞–љ–і—А –Ґ–∞—А–∞—В–Њ—А–Є–љ —А–∞–Ј–Њ–±—А–∞–ї –њ—А–∞–Ї—В–Є–Ї—Г –љ–µ–≤–µ—А—В–Є–Ї–∞–ї—М–љ–Њ–≥–Њ —Г–њ—А–∞–≤–ї–µ–љ–Є—П –≤ —Г—Б–ї–Њ–≤–Є—П—Е –Ї—А–Є–Ј–Є—Б–∞
–Ф–Є—А–µ–Ї—В–Њ—А –њ–Њ –Ш–Ґ ¬Ђ–†–Њ—Б–±–∞–љ–Ї–∞¬ї –Р–ї–µ–Ї—Б–∞–љ–і—А –Ґ–∞—А–∞—В–Њ—А–Є–љ —А–∞–Ј–Њ–±—А–∞–ї –њ—А–∞–Ї—В–Є–Ї—Г –љ–µ–≤–µ—А—В–Є–Ї–∞–ї—М–љ–Њ–≥–Њ —Г–њ—А–∞–≤–ї–µ–љ–Є—П –≤ —Г—Б–ї–Њ–≤–Є—П—Е –Ї—А–Є–Ј–Є—Б–∞
 –Ф–Є—А–µ–Ї—В–Њ—А –њ–Њ –Ш–Ґ Tablogix –Э–Є–Ї–Њ–ї–∞–є –У–∞–ї–Ї–Є–љ –њ—А–µ–і—Б—В–∞–≤–Є–ї –і–Њ–Ї–ї–∞–і ¬Ђ–Ъ–∞–Ї–Є–µ —Г—А–Њ–Ї–Є –Є–Ј–≤–ї–µ–Ї–ї–∞ –Ї–Њ–Љ–њ–∞–љ–Є—П Tablogix –Є–Ј —А–µ–Ј–Ї–Њ –Є–Ј–Љ–µ–љ–Є–≤—И–µ–є—Б—П —Б–Є—В—Г–∞—Ж–Є–Є. –Ю–њ—Л—В –Њ—Б–љ–Њ–≤–∞–љ–љ—Л–є –љ–∞ —А–µ–∞–ї—М–љ—Л—Е —Б–Њ–±—Л—В–Є—П—Е¬ї
–Ф–Є—А–µ–Ї—В–Њ—А –њ–Њ –Ш–Ґ Tablogix –Э–Є–Ї–Њ–ї–∞–є –У–∞–ї–Ї–Є–љ –њ—А–µ–і—Б—В–∞–≤–Є–ї –і–Њ–Ї–ї–∞–і ¬Ђ–Ъ–∞–Ї–Є–µ —Г—А–Њ–Ї–Є –Є–Ј–≤–ї–µ–Ї–ї–∞ –Ї–Њ–Љ–њ–∞–љ–Є—П Tablogix –Є–Ј —А–µ–Ј–Ї–Њ –Є–Ј–Љ–µ–љ–Є–≤—И–µ–є—Б—П —Б–Є—В—Г–∞—Ж–Є–Є. –Ю–њ—Л—В –Њ—Б–љ–Њ–≤–∞–љ–љ—Л–є –љ–∞ —А–µ–∞–ї—М–љ—Л—Е —Б–Њ–±—Л—В–Є—П—Е¬ї
 –Т —Д–Њ–є–µ –Ј–∞–ї–Њ–≤ —Д–Њ—А—Г–Љ–∞ —Б–≤–Њ–Є —А–µ—И–µ–љ–Є—П –њ—А–µ–і—Б—В–∞–≤–Є–ї–Є –Ш–Ґ-–Ї–Њ–Љ–њ–∞–љ–Є–Є —А–∞–Ј–ї–Є—З–љ–Њ–≥–Њ –њ—А–Њ—Д–Є–ї—П
–Т —Д–Њ–є–µ –Ј–∞–ї–Њ–≤ —Д–Њ—А—Г–Љ–∞ —Б–≤–Њ–Є —А–µ—И–µ–љ–Є—П –њ—А–µ–і—Б—В–∞–≤–Є–ї–Є –Ш–Ґ-–Ї–Њ–Љ–њ–∞–љ–Є–Є —А–∞–Ј–ї–Є—З–љ–Њ–≥–Њ –њ—А–Њ—Д–Є–ї—П
 –У–Њ—Б—В–Є —Д–Њ—А—Г–Љ–∞ –њ–Њ–ї—Г—З–Є–ї–Є –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М –≤–µ—Б—В–Є –љ–µ–њ–Њ—Б—А–µ–і—Б—В–≤–µ–љ–љ—Л–є –і–Є–∞–ї–Њ–≥ —Б –њ—А–µ–і—Б—В–∞–≤–Є—В–µ–ї—П–Љ–Є –Ї–Њ–Љ–њ–∞–љ–Є–є
–У–Њ—Б—В–Є —Д–Њ—А—Г–Љ–∞ –њ–Њ–ї—Г—З–Є–ї–Є –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М –≤–µ—Б—В–Є –љ–µ–њ–Њ—Б—А–µ–і—Б—В–≤–µ–љ–љ—Л–є –і–Є–∞–ї–Њ–≥ —Б –њ—А–µ–і—Б—В–∞–≤–Є—В–µ–ї—П–Љ–Є –Ї–Њ–Љ–њ–∞–љ–Є–є
 –≠–Ї—Б–њ–Њ–Ј–Є—Ж–Є—П –±—Л–ї–∞ –њ—А–µ–і—Б—В–∞–≤–ї–µ–љ–∞ –±–Њ–ї–µ–µ —З–µ–Љ –Є–Ј–≤–µ—Б—В–љ—Л–Љ–Є –Є –∞–Ї—В—Г–∞–ї—М–љ—Л–Љ–Є –Ї–Њ–Љ–њ–∞–љ–Є—П–Љ–Є
–≠–Ї—Б–њ–Њ–Ј–Є—Ж–Є—П –±—Л–ї–∞ –њ—А–µ–і—Б—В–∞–≤–ї–µ–љ–∞ –±–Њ–ї–µ–µ —З–µ–Љ –Є–Ј–≤–µ—Б—В–љ—Л–Љ–Є –Є –∞–Ї—В—Г–∞–ї—М–љ—Л–Љ–Є –Ї–Њ–Љ–њ–∞–љ–Є—П–Љ–Є
 –Ю—Б–≤–Њ–±–Њ–і–Є–≤—И–Є–µ—Б—П –љ–∞ —А—Л–љ–Ї–µ –љ–Є—И–Є –њ–Њ—Б–ї–µ —Г—Е–Њ–і–∞ –Ј–∞–њ–∞–і–љ—Л—Е –≥–Є–≥–∞–љ—В–Њ–≤ –Ј–∞–њ–Њ–ї–љ—П—О—В —А–Њ—Б—Б–Є–є—Б–Ї–Є–µ –≤–µ–љ–і–Њ—А—Л
–Ю—Б–≤–Њ–±–Њ–і–Є–≤—И–Є–µ—Б—П –љ–∞ —А—Л–љ–Ї–µ –љ–Є—И–Є –њ–Њ—Б–ї–µ —Г—Е–Њ–і–∞ –Ј–∞–њ–∞–і–љ—Л—Е –≥–Є–≥–∞–љ—В–Њ–≤ –Ј–∞–њ–Њ–ї–љ—П—О—В —А–Њ—Б—Б–Є–є—Б–Ї–Є–µ –≤–µ–љ–і–Њ—А—Л
 –Ю–і–љ–∞ –Є–Ј –≤–∞–ґ–љ–µ–є—И–Є—Е —З–µ—А—В CNews Forum вАФ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М –љ–µ—Д–Њ—А–Љ–∞–ї—М–љ–Њ–≥–Њ –Њ–±—Й–µ–љ–Є—П
–Ю–і–љ–∞ –Є–Ј –≤–∞–ґ–љ–µ–є—И–Є—Е —З–µ—А—В CNews Forum вАФ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М –љ–µ—Д–Њ—А–Љ–∞–ї—М–љ–Њ–≥–Њ –Њ–±—Й–µ–љ–Є—П
